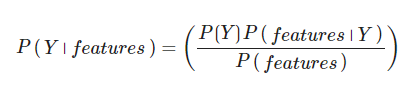This article contains affiliate links. For more, please read the T&Cs.
Start (or continue) your data science journey here with these amazing books.
You may have heard the phrase “data is the new oil”. Regardless of your feelings about fossil fuels, it certainly contains in it more than a drop of truth.
It follows that if data is the new oil, data science is the engine that drives the new economy. In only a short time, data science has become arguably the hottest industry in the world, and it does not yet show any signs of slowing down.
One unique character of data science as a field is that there are many, varied pathways to become involved in it. Although a traditional path of a university degree is a great path to get into the industry, data science might also be one of the best fields for aspiring self-taught practitioners (after all, that’s why you are here!). Between free public datasets, cheap (often free) compute power and myriad of self-learning resources, all you need to teach yourself data science is some patience and commitment.
Having said that, we here at Data Courses understand that it can feel like there are too many resources out there and it can be overwhelming to decide where to start.
Not to worry. We’ve done the research and put together a shortlist of books that we think would get you well on your journey to becoming a data scientist. Take a look – also, many of the listed books are available for free!
Background Material – Statistics & Python
A solid grasp of statistics is highly recommended (if not absolutely mandatory) if you are looking to become a data scientist; and some programming proficiency is definitely required to follow most data science books out there. So, here we list material to help you either get a good grounding in data science (statistics), and with Python, which is our language of choice.
The Signal and the Noise: Why So Many Predictions Fail–but Some Don’t
This book by Nate Silver is now a classic. Silver gained fame as a political forecaster during the 2012 U.S. elections, before more recently going on to found the famous data-journalism website FiveThirtyEight.
The appeal of The Signal and the Noise is in delivering examples of interesting prediction (i.e. modeling) case studies, that are objective, detailed yet approachable and digestible. This book is fantastic for helping the reader develop an intuitive understanding of how to use data to develop models the right way. There is a focus throughout the book on why models actually come out with the wrong predictions despite the mass amounts of data available to modelers.
Lessons that are covered in the book include:
- Understanding that many economists and modelers in other fields try to predict outcomes too narrowly and are overconfident in their results
- That models, as good as they can be, need to be reviewed by a human to ensure they’re not going awry
- There are means of using Bayes’s theorem to understand how you can get errors in any models predictions
Available on Amazon.
Bayesian Methods for Hackers: Probabilistic Programming and Bayesian Inference
What does it mean to have 85% of observations indicate result X? Does it mean the same thing as there being an 85% chance of result X occurring? (hint: no)
Understanding of Bayesian methods are critical for data scientists. Yet, many books on Bayesian statistics can be inaccessible, and worse, boring. Which is unfortunate, because it is a fascinating subject.
This book is written with programmers in mind. As a result, mathematics is kept to a minimum, and it provides plenty of examples along the way to develop your intuition. The book starts with an introduction to what Bayesian equations and math really mean for statistical analysis and how they can influence your work as well as the mathematics behind them. It then goes onto covering the PyMC Python library that is used throughout the book to provide practical examples in Python.
The book then goes on to cover the Law of Large Numbers and the Disorder of Small Numbers concepts to readers throughout the fourth chapter while providing many examples to help you get your head around the data. This is followed by an extensive chapter on loss functions and machine learning using Bayesian methods. The book is closed with a chapter on the concept of priors which leads into the last chapter on a very practical note examining A/b testing results using Bayesian methods.
Available for free here, and also on Amazon.
An Introduction to Statistical Learning
This book is written in the classical ‘textbook’ mold and is based on R, not Python. But don’t get us wrong; this is an excellent book.
Its visual and code examples definitely reduce the learning curve significantly in picking up the (admittedly dense) subject matter.
It covers common and significant statistical methods for machine learning, such as linear regression, classification, tree-based methods, support vector machines, and clustering to name a few. The intro and first sections of the book cover statistical learning in detail along with some basic diagnostics and graphics you’ll need to know in any programming language (R or Python) to really dig into your data sets. As such, it is an excellent resource as a reference.
We also get a really strong understanding of resampling methods for model validation across regression and classification models. There are also sections covering polynomial and other types of regression to give us an understanding of non-linear modeling. The book then closes on two chapters around unsupervised learning, including methods of dimensionality reduction and clustering as well as extensive coverage of support vector machines (SVMs).
Or, if you are so inclined and have the patience, it is not a bad end-to-end read also, as far as these books go.
Available here.
Automate the Boring Stuff with Python
If you are new to Python (and new to programming), this is a solid starting point. On the one side of data science is statistical knowledge and on the other is knowledge of computer science, and that’s just where this book fits in. This is a book for beginners, but the author has done a great job in packing the book full of relatable, practical examples, rather than starting with hundreds of pages of unrelatable theory. They cover the Python Standard Library extensively as well as how to import other libraries for use within your scripting as well to build robust programs, all of which is extensible to data science as a discipline.
The resulting book is an easy, fast read that helps readers begin to appreciate the utility of programming while gaining familiarity with Python.
Some of the examples like regular expressions, web scraping and dealing with csv/json files are also very useful for data science projects. The book includes details on how to perform many functions critical to understanding data flow and how to navigate many data types in Python. This includes searching for text in files across multiple files as well as how to create, update, move, and rename files and folders from Python itself. There is also an interesting set of examples of how to search the web and download website content to your local machine.
There is coverage of data management techniques involving Excel spreadsheets including formatting of Excel as well as some interesting coverage of managing PDF files, which may come in handy for a data scientist who is putting together a formal report for internal or external stakeholders. Some of the other functionality covered include how to send emails and text messages using Python, all of which come in handy when you’re up and running as a production data scientist or machine learning engineer that needs to monitor script and job performance along with your Data Engineers.
This book is likely to contain something for everyone.
Available here.
Data Science with Python
Python Data Science Handbook
This introductory data science book is for readers who may be familiar with Python but haven’t yet dealt much with data or who are looking to keep up with best practices. This is the best data science book on the subject to beginners we could think of.
I like the structure of this book. It starts the readers off with the fundamental tools for data analysis and manipulation in Numpy which is used for many mathematical functions and equations in Python. It then dives into Pandas which is a data management and manipulation library and is the most popular Python library in the Python ecosystem, something every data scientist using Python needs to be familiar with. There is then a full chapter on data visualization with Matplotlib, a skill that is very important in being able to convey complex data in graphical form when analyzing your data sets.
Then it goes on to practical overviews of various machine learning techniques, including examples and when they might be used. This section is really focused around an introduction of readers to the scikit-learn python library. They cover model tuning in detail as well as many machine learning models. This includes: Naive Bayes Classification, Linear Regression, Support Vector Machines, Decision Trees & Random Forests, Principal Component Analysis, K-Means, and a few other models.
From there the reader should be able to one for the next two books, having built a solid foundation. This is a book definitely worth checking out and is top of our list for getting your Python data science knowledge started.
Available here.
Deep Learning with Python
François Chollet is one of the creators of Keras, probably one of the top 2 or 3 machine learning interfaces in existence right now. One of Keras’ focus was on being a user-friendly machine learning framework, and this ethos shines through on Chollet’s book.
This book’s early pages cover the building blocks of machine learning theory without being overly mathematical, before moving on to practical, modern, examples and exercises in different fields. It also provides nice overviews of what deep learning as a concept truly is and what distinguishes it from traditional machine learning concepts in data science. There is extensive coverage of how to build neural nets and the mathematics behind them along with a section covering the fundamentals of machine learning, in case you didn’t read some of the earlier books.
Not only does it cover your simple regression/classification tasks, it also includes chapters on relatively complex subjects such as computer vision (and CNNs), texts (and RNNs), and even generative models (including GANs).
Yes, the materials covered are vast and wide; but it somehow never feels overwhelming or rushed.
Did I mention that this book is available here? Go get it.
Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow
As the name suggests, Geron’s highly touted book is another that is focussed more on the practical than the theoretical.
One difference between this book and Chollet’s is that its examples employ multiple packages; for instance easing the readers into machine learning with exercises using scikit-learn, before moving onto tensorflow for more complex models.
The book takes you on a guided example of a machine learning project using the scikit-learn library so you understand the full framework you’ll be working with in the future. You get to explore model development and training/testing of Support Vector Machines, Decision Trees, Random Forest, and ensemble methods. From there you dive into the TensorFlow library for Python and you learn how to build and train neural nets, architect them, and learn techniques for scaling models.
Geron has just updated the book and this second edition also covers Keras as a higher-level wrapper / interface for Tensorflow.
Available on Amazon. Associated GitHub repo.
Natural Language Processing with Python
As they say, this is an oldie but a goodie. While some might argue (rightly) that the current approaches to machine learning with text have moved on somewhat, this is a great introduction to the field of natural language processing.
The book provides a mix of theoretical backgrounds in linguistics and computational linguistics as well as lots of practical examples with Python & NLTK, the classic language processing Library. As the book does not assume any Python knowledge, it is also well-suited for beginners. It starts with some basic domain knowledge about what natural language processing (NLP) truly involves and some of the jargon that goes with it. Then it jumps into how to process text using Python, a critical data crunching skill for data analysts and scientists alike.
The book progresses to more advanced topics such as analyzing grammar and sentence structure as well as the meaning of sentences as you get deeper into it. It ends on a chapter on managing linguistic data which walks through the high-level architecture of how you manage a corpus, or a large grouping of text (articles, etc.) and how that data is later manipulated to find insights.
Available on Amazon.
Deep Learning
Practical books are great, but for serious data science practitioners, a strong theoretical foundation might be just as important, especially in the long run. For those looking to shore up their understanding of the underpinning theories behind machine learning algorithms and processes, this book might be just right.
This book is comprehensive in subject matter; guiding the reader by starting with the fundamental mathematics needed to progress throughout the book such as linear algebra and probability and information theory, before moving on to theory on more complex and topics such as regularisation, optimization, CNNs, RNNs. There is also deep and extensive coverage of practical methodologies and applications of deep learning to real-world problems.
There is also some detail at the end of the book regarding Monte Carlo Methods covering importance sampling, Markov Chains, and Gibbs Sampling.
It also expands the reader’s mind further than many books in that it devotes an entire section to state of the art research, which might be of interest once you’ve become comfortable with the more widespread techniques and practices. What may be difficult about this book is that it spans over 599 pages in its hardcover format, but don’t be overwhelmed by its depth as you can always take the contents section by section as needed.
Available on Amazon.
Bonus book – ML Strategy:
Machine Learning Yearning
This upcoming book by Andrew Ng is technically not available yet (it is in draft as of mid-Feb 2020), but a copy of it is accessible by signing up to a mailing list. Ng is as close a machine learning expert can be to a ‘celebrity’, having taught at Stanford, founded Coursera and now DeepLearning.ai.
This book is aimed at those at managerial levels in organizations that are looking to implement data science / AI projects. As such, it focuses on high-level concepts and developing intuitive understandings of machine learning concepts and potential problems that may arise during a project.
I think that practitioners can also find a lot of value in this book, though, whether it is for themselves or in improving their skills in communicating esoteric machine learning concepts to laypeople.
Available here (for now)
What’re you waiting for? Get out there and get reading the best data science books out there! If we have missed your favorites, let us know.