Pandas is a predominant data analysis and manipulation library for Python. One of the core data structures of Pandas is DataFrame which stores data in labelled rows and columns.
There are many methods to create a DataFrame. A common one is to use a list which is a built-in data structure of Python. Lists can store any data type or even a mixture of data types. Following is a list that contains 5 integers.
list_a = [1, 2, 3, 4, 5]We can pass a list as an argument to the DataFrame function of Pandas. As a result, we will get a DataFrame with one column.
import pandas as pd
df = pd.DataFrame(list_a)
We are not likely to encounter a data frame with one column. Depending on the task and operation, a data frame contains several columns. Since it is getting easier and less expensive to collect and store data, the size of data provided for a task gets larger in both dimensions.
We can use lists to create a data frame with multiple columns as well. There are two approaches. Depending on how we pass the lists to the DataFrame function, Pandas generates the data frame in a different way.
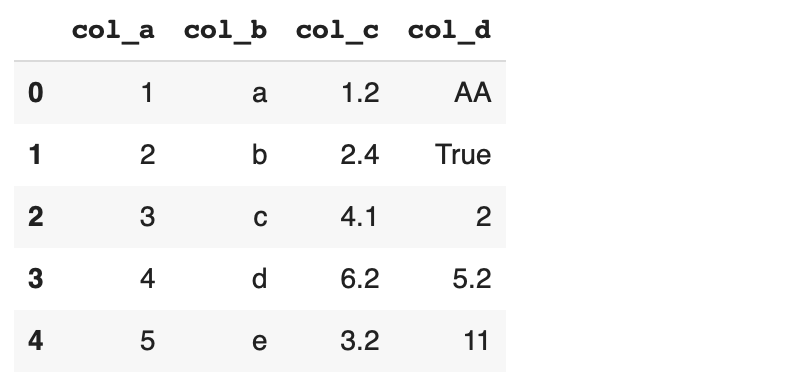
The first one is to use a separate list for each column. The lists are passed to the DataFrame function as values of a dictionary. The column names are specified using the dictionary keys. The items in lists constitute the row values. Thus, each list must have the same number of items. Let’s create a data frame with 4 columns and 5 rows.
df = pd.DataFrame({
'col_a': [1, 2, 3, 4, 5],
'col_b': ['a', 'b', 'c', 'd', 'e'],
'col_c': [1.2, 2.4, 4.1, 6.2, 3.2],
'col_d': ['AA', True, 2, 5.2, 11]
})List can store values of any data type or even a mixture of data types. It provides the flexibility to create a data frame with any type of values. Here is the data frame we have just created:
The second method to create a data frame with multiple columns with lists is to use nested lists. Since list items can be of any data type, we can create a list of lists. The list_b in the following code block is a list that contains 4 items and each item is a list of length 3.
list_b = [
[1, 'a', 2.3],
[4, 'c', 12.1],
[6, 'f', 1.5],
[2, 'b', 3.3]
]The DataFrame function of Pandas can be used to convert this list to a data frame. Unlike the previous method, we do not have to pass the list in a dictionary. There is one difference to keep in mind though.
In the previous method, each list is passed to a different column so we explicitly define the values in a particular column. In this method, the nested lists do not constitute the columns. For instance, the first nested list contains 1, a, and 2.3 which does not mean that the first column will include these values.
The first column includes the first items in each nested list, the second column includes the second items in each nested lists, and so on. Thus, the values of the first column are 1, 4, 6, and 2. Let’s actually create the data frame and see all of the columns.
df = pd.DataFrame(list_b)
If you wonder why Pandas generates the data frame in this way, think about what rows and columns represent. A row in a data frame is an observation or data point. The columns represent features or attributes that explain the observations (i.e. rows).
Consider we have a data frame of used cars. There are 4 columns which contain the following information:
- Year
- Brand
- Mileage
- Price
Each row in the data frame represents a car. In case of the nested lists, each nested list represents a car so they constitute the rows, not the columns. It is like recording the features of a car in a list and then combine each list in a bigger list.
When using nested lists, Pandas assigns integers as column names by default. However, we can customize the column names using the columns parameter.
df = pd.DataFrame(list_b, columns=['col_a', 'col_b', 'col_c'])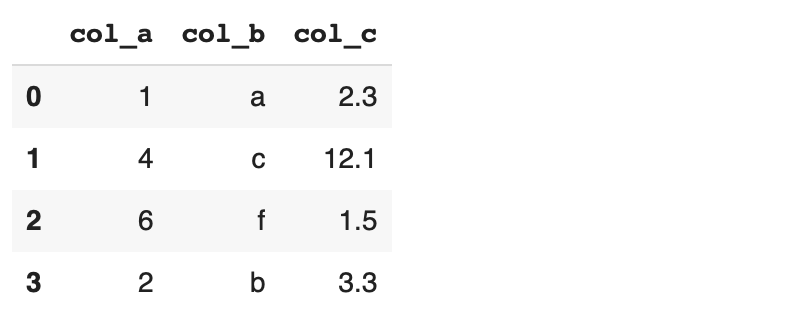
Pandas provides the from_records function that can be used to create a data frame with nested lists. It offers more functionality than the DataFrame function. Here is how the from_records function is used:
df = pd.DataFrame.from_records(list_b)
A highly useful parameter of the from_records function is the exclude parameter. It allows for excluding items in the nested lists from using in the data frame. If we want to exclude the second items and create a data frame using only the first and third items, we pass 1 to the exclude parameter.
df = pd.DataFrame.from_records(list_b, exclude=[1])
It is a useful parameter because we may not always need all of the features. Pandas provides the drop function for removing a column or multiple columns from a data frame but it is more practical not to read the redundant or unnecessary columns at the beginning.
The from_records function has the columns parameter to customize the columns names as well. Please keep in mind that if you change the column names and want to exclude a column or multiple columns, you should pass the new column names to the exclude parameter.
We can also use a list of tuples or a mixture of tuples, lists, and other iterables. We can even use a string as a nested item. Both the DataFrame and from_records functions accept these structures and create a data frame as long as the nested items have the same length.
list_c = [
(100, 'A', 22.3),
(200, 'D', 34.1),
[500, 'D', 18.5],
'abc'
]The list_c consists of 2 tuples, 1 list, and 1 string. The ‘abc’ string is regarded as an utterable so it acts like a list of 3 items which are a, b, and c. We can pass this list to the DataFrame function just as before.
df = pd.DataFrame(list_c)
We have done several examples to demonstrate how lists can be used to create a Pandas data frame. A list can represent a column or a row depending on our approach. In both ways, lists serve as a highly practical method of creating data frames.