“Decision Tree” is a type of supervised learning machine learning algorithms family which can solve both, regression and classification problems. Decision trees machine learning is to construct a training model that can be used to predict the target variable’s class or value by learning the basic decision rules from prior data (training data). To be more specific, a decision tree is a type of a probability tree that helps make a decision about a kind of a process.
When using this algorithm to predict a record’s class label, we must start at the top of the tree. The root & record attributes are compared. Based on this, we follow the branch that corresponds to that value and then move on to the next node. A decision tree is used in many real life situations such as business, and even engineering.
Types of Decision Trees
There are 2 types of decision trees based on the target variable:
Categorical Variable: Where the target (y) variable is categorical
Continuous Variable: Where the target (y) variable is continuous
Components of Decision Trees
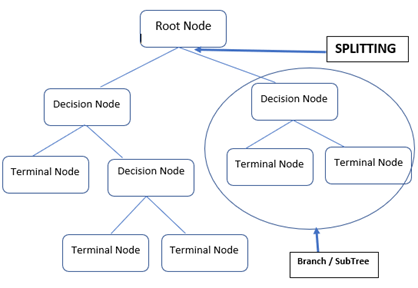
- Root node: Symbolizes the total sample, which is then separated into two or more homogeneous groups
- Parent & child nodes: A parent node of sub nodes is a node that is divided into sub nodes, whilst sub nodes are the “children” of a parent node
- Decision node: Formed when a sub node splits into more sub nodes
- Splitting: Is the method of splitting a node into two/more sub nodes
- Pruning: Is the method of eliminating sub nodes from a decision node
- Terminal / Leaf nodes: These are the nodes that do not split
- Sub-Tree / Branch: A sub-tree/branch is a part of the tree
Assumptions While Creating A Decision Tree
Here are a few assumptions made while creating a decision tree:
- At first, a complete training dataset is regarded as the root
- Basis attribute values and records are dispersed recursively
- Using some statistical approaches (such as those listed below), it is possible to place attributes as the tree’s root or internal node
How To Select An Attribute As Root Node
Choosing the attribute to insert at the root / at different levels of decision tree as internal nodes is a complex step since the dataset contains multiple features (variables). The problem cannot be solved by selecting any node at random as the root because it may end up with low accuracy & poor results.
This is solved by utilizing an algorithm such as Gini index, information gain, etc. Every attribute’s value will be calculated using these algorithms. The values are sorted, and characteristics are ordered in the tree, with the attribute having the highest value at the top (in the case of information gain).
Building Simple Decision Tree (Classification) Model Using Scikit-learn
We’ll using a dataset from Kaggle – Diabetes.
Download the .csv files and load them into the Jupyter environment.
Data Dictionary:


Data Import:
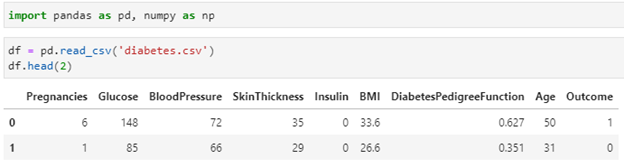
import pandas as pd, numpy as np
df = pd.read_csv(‘diabetes.csv’)
df.head(2)
Feature Selection:

feature = [‘Pregnancies’, ‘Insulin’, ‘BMI’, ‘Age’,’Glucose’,’BloodPressure’,’SkinThickness’,’Insulin’]
X = df[feature] # ALl_Features
y = df.Outcome # Target
Data Split:

from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=1) # 75% training & 25% test
Now let’s build a very simple, intuitive decision tree model:

from sklearn.tree import DecisionTreeClassifier
from sklearn import metrics
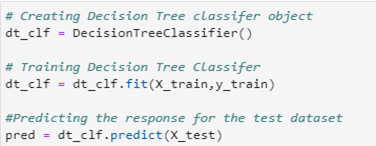
# Creating Decision Tree classifer object
dt_clf = DecisionTreeClassifier()
# Training Decision Tree Classifer
dt_clf = dt_clf.fit(X_train,y_train)
#Predicting the response for the test dataset
pred = dt_clf.predict(X_test)
Let’s evaluate the decision tree classifier:

print(“Accuracy:”,metrics.accuracy_score(y_test, pred))
In this tutorial on decision tree machine learning, we have achieved 70% accuracy that can be improved by tuning some parameters.
Let’s visualize the decision tree:
First, let’s fix the depth of decision tree classifier.
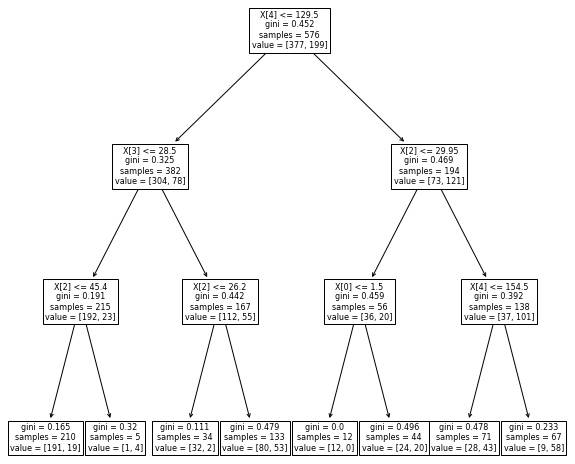
# Creating Decision Tree classifer object
dt_clf = DecisionTreeClassifier(max_depth=3)
from sklearn import tree
import matplotlib.pyplot as plt
plt.figure(figsize=(10,10)) # set plot size (denoted in inches)
tree.plot_tree(dt_clf, fontsize=8)
plt.show()
Pros & Cons of Decision Trees:
Pros:
- A decision tree is simple to understand
- It takes the same approach to decision-making that humans do in general
- The visualizations of Decision Tree Model can make it easier to understand
- Can work with numerical features
- Simple to understand and follow a pattern that is akin to human thought. In other words, it can be described as a set of questions / business rules
- Prediction is a quick process. It’s a series of operations that you perform until you reach a leaf node
- Can be modified to deal with missing data without the need for data imputing
Cons:
- In decision tree, there is a high risk of overfitting
- In comparison to other machine learning techniques, it has a low prediction accuracy
- In a decision tree with categorical variables, information gain leads to a biased response towards attributes with more categories
- When there are a lot of class labels, calculations can get complicated
- The tree can be unstable
- They are often relatively inaccurate
Summary
We’ve learned that decision trees are easy to comprehend and use, and they also work well with large datasets. There are three main aspects to decision trees: decision nodes, chance nodes (which denotes probability), and end nodes (denoting conclusion). Decision trees algorithm can be used to with large datasets, and they can be pruned to avoid overfitting if needed.
Despite their many advantages, decision trees are not appropriate for all forms of data, such as datasets with imbalances or continuous variables.
References
- Jupyter Book Online
- Kaggle – Diabetes dataset
- Official documentation of Decision Tree