Scikit-learn/Sklearn (formerly scikits. learn) is perhaps Python’s most useful machine learning (ML) library. Regression, dimensionality reduction, classification and clustering are only a few of the useful methods in the “Sklearn Library” for statistical modeling and for creating ML models.
Origin Of Scikit-learn
Data scientist David Cournapeau created the open source scikit-learn package as a Google Summer of Code Project. Later, Matthieu Brucher joined the project and began using it as part of his thesis research. The French national research institution, the National Institute For Research in Digital Science and Technology (Inria) became involved in 2010, and the first public update (v0.1 beta) was released in late January 2010.
Inria, Google, French company Tinyclues, and the Python Software Foundation have all contributed to the project financially, and it has over 30 active contributors today.
Some Components
- Supervised learning algorithms: Consider any supervised machine learning algorithm you’ve heard of; chances are it’s included in scikit-learn. The scikit-learn toolbox includes everything, from linear regression to Stochastic Gradient Descent (SGD), decision tree, random forest, etc. One of the main reasons for scikit-learn’s popularity is the development of ML algorithms. Here are a few examples:
- Random forest
- Decision tree
- Ridge regression
- Unsupervised learning algorithms: Once again, the offering includes a wide range of machine learning algorithms ranging from principal component analysis (PCA), clustering, unsupervised neural networks and factor analysis
- Cross-validation: There are various methods for testing the accuracy of supervised models on unseen data using Sklearn
- Clustering: It is an unsupervised learning technique that automatically groups related objects into sets. Few examples:
- K-means
- Mean shift
- Spectral clustering
- Hierarchical clustering
- Dimension reduction: The method of reducing the number of random variables is known as dimensionality reduction. Few examples:
- Principal component analysis
- Non-negative matrix factorization (NMF)
- Feature-selection techniques
Model selection is the action of comparing, validating, and selecting parameters and models. It utilizes algorithms such as grid search, cross-validation, and metric functions. Scikit-learn provides all the demonstrable algorithms and methods in easily accessible APIs.
- Data preprocessing: One of the first and most critical steps in the machine learning process is the preprocessing of data, which includes features extraction and normalization. Normalization converts features into new variables, usually with a zero mean and a unit variance, but often with a value between a given minimum and maximum, usually 0 and 1. Feature extraction converts text or photographs into numbers that can be used in machine learning
- Feature selection: It is used to define useful attributes for creating supervised models
- Various dummy datasets: This is useful when studying scikit-learn. You can practice machine learning on different datasets provided (ex- IRIS dataset). Having them on hand while studying a new library is extremely beneficial
- Parameter tuning: It is used to get the best out of supervised models
- Manifold learning: This is a technique for summarizing and envisioning complex multidimensional data
Why Use Scikit-learn In Machine Learning
Scikit-learn is both, well-documented and straightforward to learn/use if you want an introduction to machine learning, or if you want the most up-to-date ML testing tool. It lets you construct a predictive data model with a few lines of code and then apply that model to your data as a high-level library. It’s flexible and integrates nicely with other Python libraries such as Matplotlib for charts, Numpy for numerical computations, and Pandas for DataFrames.
Scikit-learn contains many supervised & unsupervised learning algos. Most importantly, it is by far the simplest and cleanest ML library. It was created with a software engineer’s perspective. Its central API architecture revolves around being simple to use while still being versatile and flexible for research endeavors. Because of its robustness, it is suitable for use in any end-to-end ML project — from research to production deployments. It is based on the machine learning libraries mentioned below:
NumPy: is a Python library that allows you to manipulate multidimensional arrays and matrices. It also includes a large set of mathematical functions for performing various calculations
SciPy: is an environment of libraries for performing technical programming tasks
Matplotlib: is a library that can be used to build different charts and graphs
(Tip: Please do refer to the Andreas Mueller (one of the main scikit-learn contributor) cheat sheet for machine learning. It is a very effective representation for comprehending the scope of Scikit’s ML algorithms.)
Overview Of Few Machine Learning Algorithms
- Linear regression: The relationship between two factors is shown or predicted using linear regression models. The factor being predicted is known as the “dependent variable”. The “independent variables” are the factors that are used to predict the value of the dependent variable. Each observation in linear regression has two values. One of them represents the dependent, while the other means the independent variable. In this basic model, a straight line approximates the relationship between both the variables.
- Logistic regression: Logistic regression is another statistical methodology that machine learning has borrowed. It’s the form of choice for binary classification issues (problems with two class values). Like linear regression, the purpose of logistic regression is to find the values for the coefficients that weigh each input variable. In contrast to linear regression, the output estimate is transformed using a non-linear function known as the logistic function.
- Decision trees: It is a popular form of ML algorithm, and often used in predictive modeling. Decision tree model is often described as a binary tree. The latter is made up of data structures and algorithms. A split on a single variable (z) is represented by each node (variable should be numeric). Output variable (y) is used to make a prediction. Predictions are made by processing through the tree’s splits before reaching a leaf node; then outputting the class value at the node. Trees are very fast to learn and even faster to predict.
- Random forest : It is a set of decision trees. Each tree is categorized, and the tree “votes” for that class to classify a new object based on its attributes. The classification with the most votes is chosen by the forest (overall, the trees in the forest).
Here’s how each tree is planted and grown:
If the training set contains X cases, a sample of X cases is selected at random. This sample will serve as the tree’s training package.
Let’s assume A input variables, a number y less than A is set down so that variables are randomly picked from input dataset at each node, and the best split on y is used to split the node further. y’s value is kept constant.
Now, each tree is grown to its full potential.
- Gradient boosting algorithm : These are boosting algorithms that are used when large amounts of data must be processed to make accurate predictions. Boosting is an ensemble learning algorithm that improves robustness by combining the predictive strength of many base estimators. To put it another way, it combines many weak or average predictors to create a good predictor.
Let’s Build A Simple Machine Learning Model
Consider a simple scenario wherein you must determine, based on the weather, whether to bring an umbrella or not. You have access to the training data (temperature). Your mind makes a relation between the input (temperature) and the output (temperature) (take an umbrella/not).
Now, let’s move on to an algebraic problem where the model will predict the results for us:
- Generate the dataset – Focus on the equation passed in the dataset creation.

#load libraries
import numpy as np, pandas as pd
from random import randint
limit_train = 200
count_train = 10
inp = list()
out = list()
for i in range(count_train):
_a = randint(0, limit_train)
_b = randint(0, limit_train)
_c = randint(0, limit_train)
_d = randint(0, limit_train)
equation = _a + (1/2*_b) + (5/3*_c)+ 2*_d
inp.append([_a, _b, _c, _d])
out.append(equation)
- Model training – Now that we have the training data, we can build a Linear Regression Model and feed it the training data.
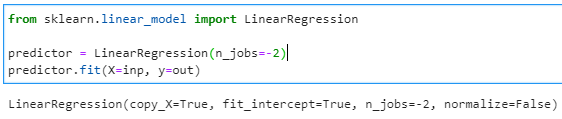
from sklearn.linear_model import LinearRegression
predictor = LinearRegression(n_jobs=-2)
predictor.fit(X=inp, y=out)
- Pass the test data set : Lets pass the test data as 1,2,3,4.
As per the equation the output should be:
1 + (1/2)*2 + (5/3)*3 +2*4= 15
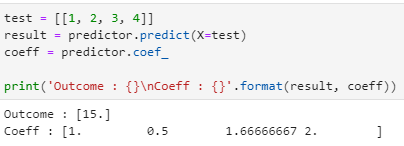
test = [[1, 2, 3, 4]]
result = predictor.predict(X=test)
coeff = predictor.coef_
print(‘Outcome : {}\nCoeff : {}’.format(result, coeff))
As the above model had access to the training data, it determined the weights and the inputs to produce the needed output. When test data was passed, it got the correct response.
Summary
This was a high-level introduction to one of Python’s most efficient and adaptable machine learning libraries. Sklearn, that started out as a Google-led project, has not only determined the way models are written, but it has also broken new ground in Python for machine learning, sculpting the language and, to some degree, the ecosystem. Because of this, Sklearn’s outcome on science, ML, and automation gains importance.