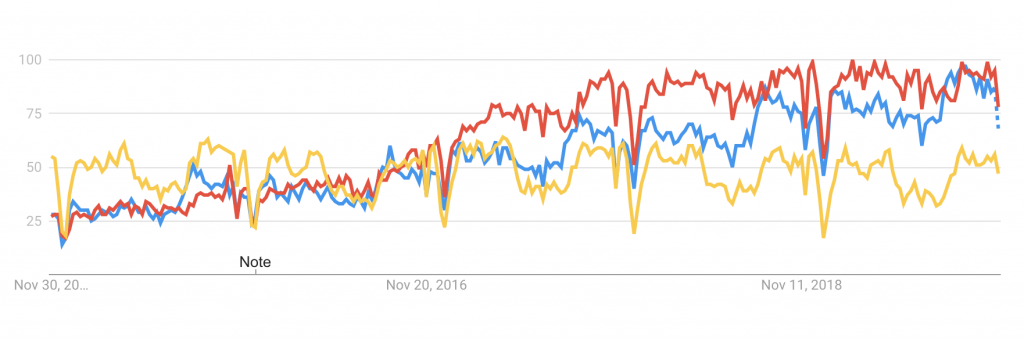
As data analytics, data science, and data engineering have exploded in popularity and growth as concepts, they’ve had some support from the open source software development community, including those supporting the Pandas library. With the huge interest in data science, machine learning, and data analysis (blue, red, and yellow respectively) Pandas has acted as a pillar of the growth of the Python programming languages rise over the past several years.
What is Pandas?
Pandas is an open-source Python library designed for data analysis, data transformations, and data manipulation. As of the time of this article, 25 versions of Pandas have been released with increasing usage year over year since its creation by Wes McKinney.
Its main features include the following:
- Handling of missing data
- Merging and Joining of data sets
- Support for Time-Series analysis
- Reshaping and pivoting of datasets
- Manipulation of standard Python library objects to and from DataFrames
- GroupBy functions similar to those in SQL
- Read, Write, Update, and Delete features on datasets
- Support for databases including BigQuery, postgres, and other standard databases
Why has it been adopted so quickly?
According to Stack Overflow, Pandas usage has grown significantly since 2011. The libraries’ success is tied to the features it offers, as mentioned above, but also to the explosive growth in the data science, analytics, and engineering fields.
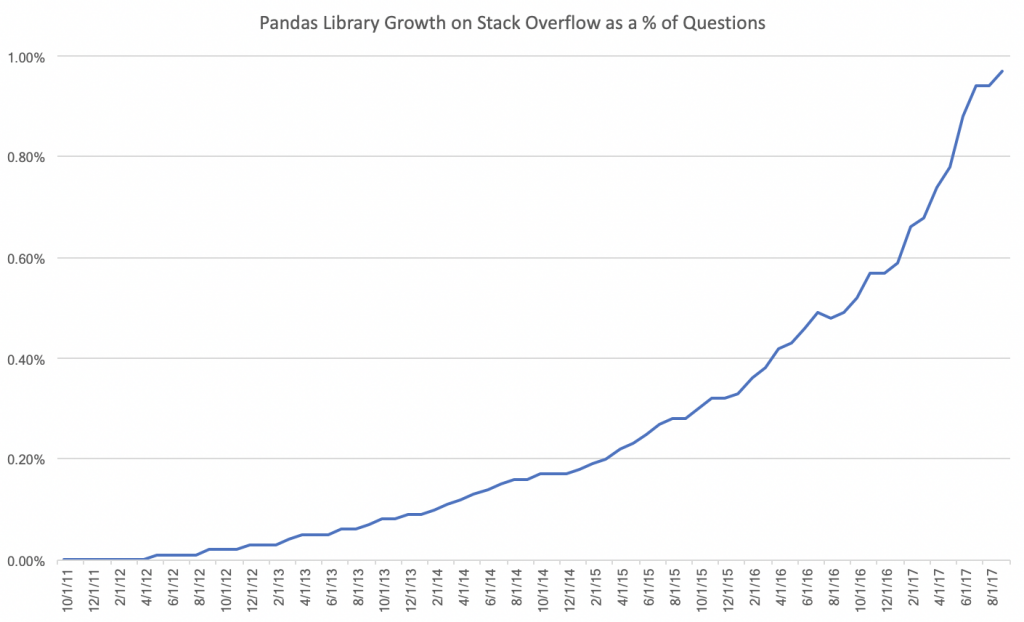
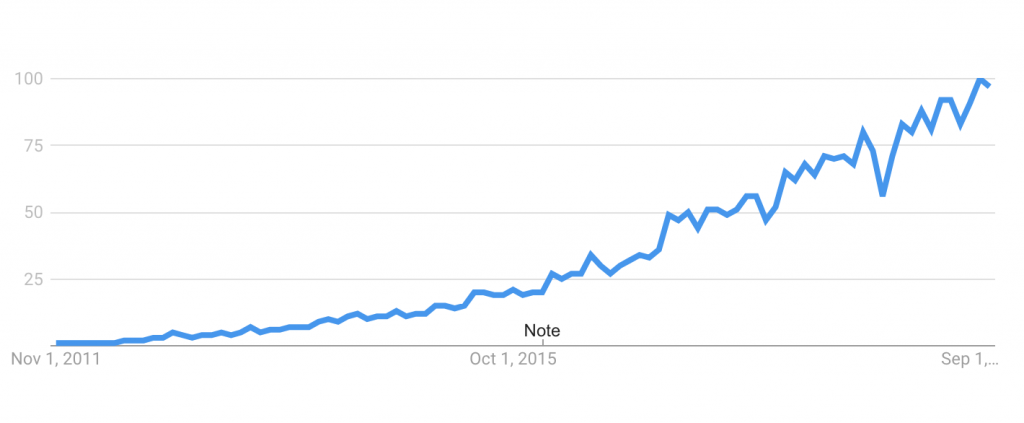
What makes Pandas so special is it’s focused on fundamental data manipulation and management tasks. Python itself is used for a variety of purposes including web development, DevOps, game development, and data science/machine learning. Python has become the most popular programming language according to Stack Overflow’s traffic to questions regarding Python packages, which has helped Pandas rise in usage generally. The growth in usage has been so large that Stack Overflow now has more visits for Pandas tagged questions alone than for the entire javascript programming language.
As of 2010, Python initially did not have any supporting libraries to make mundane data import, manipulation, and analysis possible without a considerably heavy lift from analysts. This included basic functions such as the ability to import data from a CSV file into Python, quickly plotting data from a given data range, or performing SQL-like joins across datasets. All of this was covered by a hodge-podge of libraries such as numpy, matplotlib, scipy (to name many other libraries including the Python Standard Library).
Who contributes to Pandas?
Part of pandas rise is its large contributions expanding the library from some powerful backers. These backers include the Chan-Zuckerburg foundation, which supports the organization NumFocus. NumFocus is a non-profit focused on supporting open practices of research, data, and scientific computing. Additionally, many individual contributors provide software development to enhancing the library.
Summary
The Pandas library is dominating the data analysis field for those using Python. It continues to grow significantly in usage across various measures and doesn’t look like it is going to stop growing its user base anytime soon. Millions of views per month are being measured by StackOverflow and with more focus on data science and analytics education in the coming years, we expect the library to continue to grow.
We see the future of Pandas as bright. It is a critical library supporting the backbone libraries for statistical modeling, machine learning, data analysis, and data engineering in Python.