Two common data objects that are usually used in data analysis across the Python ecosystem are Pandas DataFrames and NumPy arrays. The two data types stem from different levels of abstraction from the C programming language, however they are both very compatible with one another. In this post, we’ll cover the differences between the two object types and how they’re used in data analysis. Additionally, we’ll show how to move NumPy array data in and out of Pandas DataFrame objects.
DataFrames v. NumPy Arrays
NumPy arrays and Pandas DataFrames differ in many respects. While both are designed to store matrix-style data, Pandas offers much more statistical analysis tools that are used for Exploratory Data Analysis, data transformation, and overall data management. NumPy, on the other hand, is generally a low-level means of storing data generally for analysis outside of the NumPy library by libraries such as SciPy or Statsmodels. NumPy arrays can be summed up as objects much more similar to Python Lists or Dictionaries.
Knowing some of the differences in Pandas DataFrames v. NumPy arrays is one thing, but actually using the two types of data storage together is a common activity that analysts must become familiar with.
Convert Pandas DataFrame to a NumPy Array
Converting DataFrames into NumPy Array objects is standard practice for several analysis techniques, which are not covered here. However, there are several means of achieving this with Pandas.
The first is simple and involves invoking the reset_index() function.
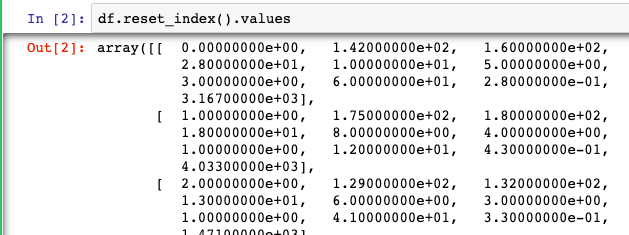
df.reset_index().valuesAn even more simplistic approach is to call DataFrame.values to get an Array output.
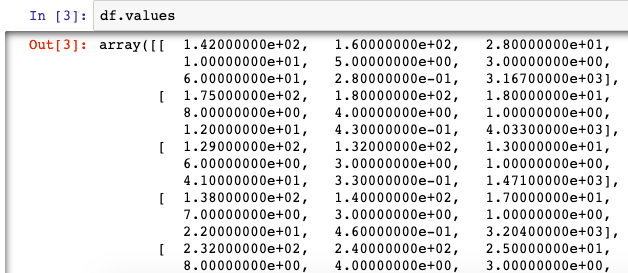
However, the best use-case is to use the function rolled out in Pandas 0.23 to convert DataFrames directly to NumPy Array objects. .to_numpy(). This can be applied to both DataFrames and Series objects in Pandas.


df.to_numpy()
df.Sell.to_numpy()Create a DataFrame from a NumPy Array
When you have an Array that you want to convert back into a Pandas DataFrame, the functions available to do this are quite simple and are similar to those that you would use to specify the importation of a dictionary or other object into a DataFrame.
For this, we specify Pandas.DataFrame(data) to read in the Array object into Pandas. The below shows us moving the data into an Array object and then back into Pandas.
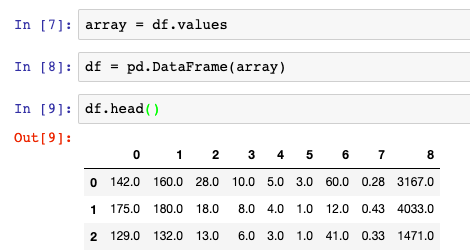
array = df.values
df = pd.DataFrame(array)While this was technically accomplished, we obviously lost some information regarding our original column headers from the original DataFrame which have now been replaced by integers (0,1,2,3, …). To resolve this we must specify the column names in our sample dataset. In this instance, we set a variable c equal to a list of our column names (Sell, etc.)
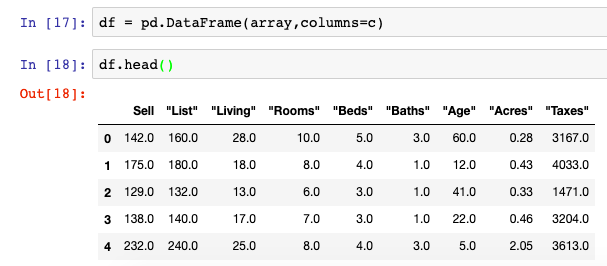
df = pd.DataFrame(array,columns=c)
df.head()Summary
We’ve covered multiple approaches to handling NumPy data when being transformed into and out of Pandas. The several techniques we’ve covered are:
- Using reset_indes().values to see data in a Numpy array
- Transforming data to an array using to_numpy()
- Reading data into Pandas DataFrames using the pandas.DataFrame() function
To find the code used in this tutorial to follow along, you can find this on our GitHub along with the full data analysis library of code on this blog.