Challenges with Pandas Data Types
When using any software, it’s critical to understand the data types that your data will be read, manipulated, and exported as a part of the analysis process. When reading data from a database, for instance, data which one may want to represent a float value could very well be read into your DataFrame as a string value, making even basic mathematical operations impossible to perform without changes to the datatype itself. Additionally, when loading data out of your DataFrame into downstream systems, even something as simple as a CSV file, we will want to know how the data is actually loaded into those systems. For the purposes of this article, we’ll only cover the first two of these problems in this post, loading data into Pandas and manipulating data types once the data is loaded.
Pandas Data Types v. Standard Python
The Python Standard library offers many types of objects and data types for manipulation within the underlying software. Thankfully, we don’t have to get into the details of this out-of-the-box data types in this post, we only need to review solutions to issues that pop up when analyzing data between Python and Pandas. We’ll cover some of these issues in our Changing Data Types section of this post.
Below we have a listing of the data types between Python, Pandas, and R (not usually covered in our blog)
| Pandas Data Type | Python Standard Library | R |
| object | character, complex, Raw | |
| int64 | int | integer, numeric |
| float64 | float | numeric |
| bool | bool | logical |
| datetime64 | NA | |
| timedelta[ns] | NA | |
| category | NA | |
| object | complex | complex |
For an extensive review of the Python Standard Library data types, see the following post by Real Python.
Identifying Data Types in a DataFrame
It’s important to understand how to analyze this data with a hands on approach, so in this post we’ll be exploring an open data set from FSU.

import pandas as pd
file_name = "https://people.sc.fsu.edu/~jburkardt/data/csv/homes.csv"
df = pd.read_csv(file_name)Once the data is imported, we’re going to make some changes to the datatypes of several columns for the purposes of showing all the core Pandas data types. In this operation we’ll create a bool, string/object, and category data type of existing fields:

df['Grouping'] = df[' "Baths"'] > df[' "Beds"']
df[' "Baths"'] = df[' "Baths"'].astype(str)
df[' "Beds"'] = df[' "Beds"'].astype('category')The next step is to review the data types as Pandas shows them within our sample DataFrame object. For this we’ll be using the .dtypes and .info() functions. In my opinion, the better of these functions i the .info() function as it handles some functionality telling us how many null values may be present in our DataFrame.
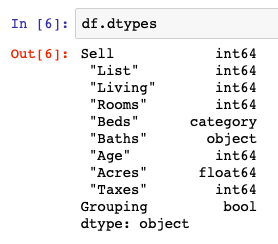
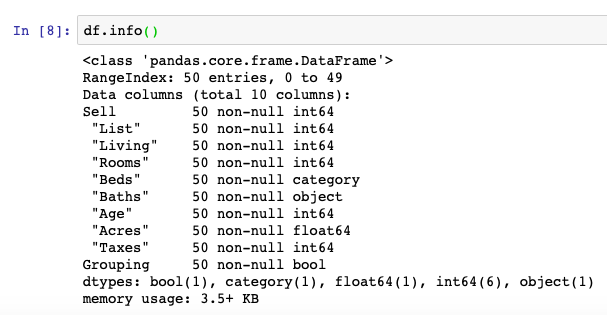
df.dtypes
df.info()Many of the operations we’ll cover here we have reviewed in a past post called Understanding Pandas DataFrame Column Contents.
Changing Data Types
The most important function to use to change data types in Pandas is the .astype() function. This function can be used across all data types and unless there are specific reasons it can’t be used (i.e. you can’t change “cats” into an integer… sorry) we will be able to transform columns relatively quickly.
We saw in our earlier section how .astype() can work and we will now show it changing some data types back to their original form.

df[' "Baths"'] = df[' "Baths"'].astype(float)
df[' "Beds"'] = df[' "Beds"'].astype(int)Once transformed, we can again use the .info() function to see what the contents of our DataFrame actually look like:
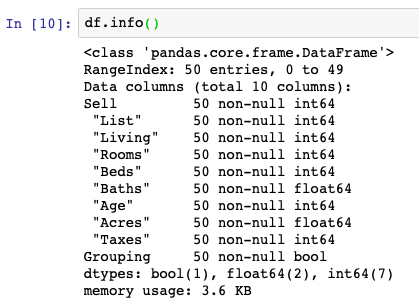
Summary
We’ve now conquered the loading, checking, and transformation of our DataFrame contents and are on our way to knowing a bit more to take us closer to owning the full ability to cleaning up our DataFrame contents.
After this tutorial, you should know how to understand Pandas data types and how to manipulate them from one form to another. For the code surfaced in the screenshots above, please visit our GitHub repository on Data Analysis and the specific Jupyter Notebook for this post, here.