JSON is one of the most common data formats available in digital and non-digital applications. As a result, there it is critical to understand how to transform JSON into a Pandas DataFrame for manipulation. A part of the challenge with JSON is the variety it’s purposely unstructured format can take, and what that will mean for the construction of a DataFrame from it’s contents.
In this post, we’ll cover several fundamental functions within Pandas to transform JSON data from its raw form into DataFrames. We covered one of these approaches in a prior post, but we will expand on this topic beyond simply using the json_normalize function to using read_json as well.
Sample JSON Datasets
We had previously covered the CitiBike system update dataset in a prior post and will continue to use its extensive JSON API in this tutorial. We’ll be specifically looking at the Station Status feed which shows which bikes are available at each station throughout the city at any given time. It’s a straight forward example of JSON data structures and helps us understand how to import the data into a DataFrame.
Using json_normalize
The most important JSON import function in Pandas is json_normalize which unnests JSON data into a columnar format for further analysis.
Before we can begin using Python to transform JSON data, we need to import the necessary libraries that will make analysis possible. These include Pandas, Requests, & JSON.

import requests
import pandas as pd
from pandas.io.json import json_normalize
import jsonNext we will access the API using Requests in a simple GET call to pull down the data from the feed into our Python environment. The resulting data, which can be seen by navigating to the URL itself, will show its values under r.json().

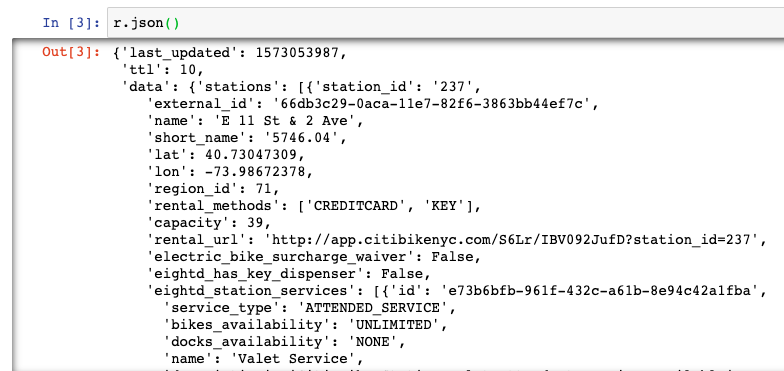
url = "https://gbfs.citibikenyc.com/gbfs/en/station_information.json"
r = requests.get(url)
r.json()The next step is to explore the contents of the JSON object by using .keys() function to see the nested layers of data stored in the object. In our case, we’re interested most in the ‘data’ tab of the JSON feed.

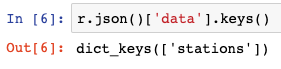
r.json().keys()
r.json()['data'].keys()The data we’re truly looking to access is stored under data and stations keys in the JSON object. The contents should look like the below:
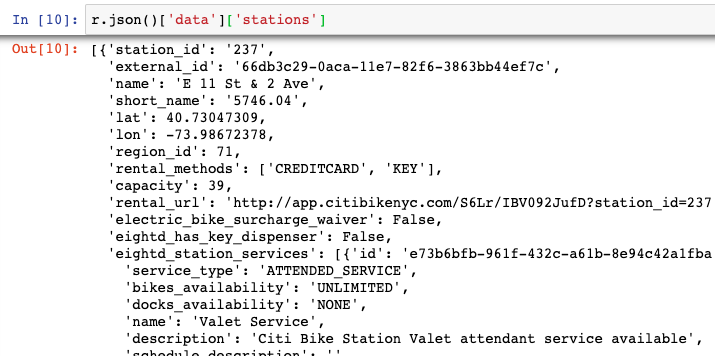
Once we confirm we have the right level of the JSON object, we can then use the json_normalize function to transform that data into a DataFrame as seen below:

r.json()['data']['stations']
stations = r.json()['data']['stations']
df = json_normalize(stations)
df.head()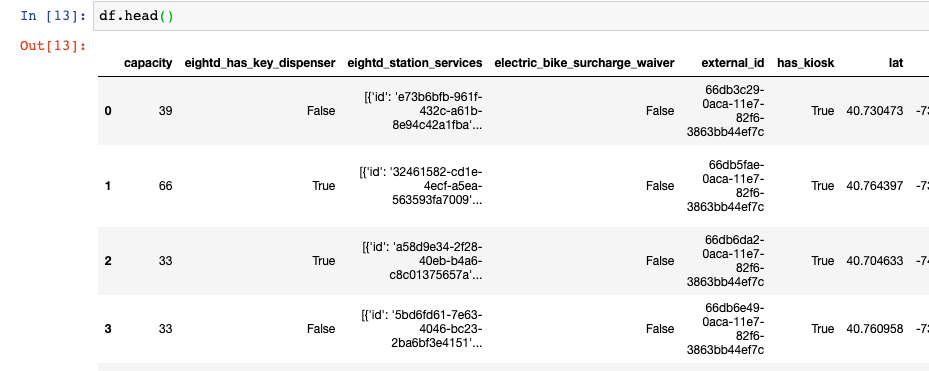
Using from_dict
One additional way of converting data from a JSON object to a DataFrame is to use the from_dict function. This said, there is one caveat here, we must confirm that the object we have stored is of type ‘dict’ once read into a variable in Python. Python automatically does this regularly with JSON objects, but not all the time. You can check this by using type(data) to your data object to confirm its type. If it is a dictionary, we can then read the data into a DataFrame as seen below:
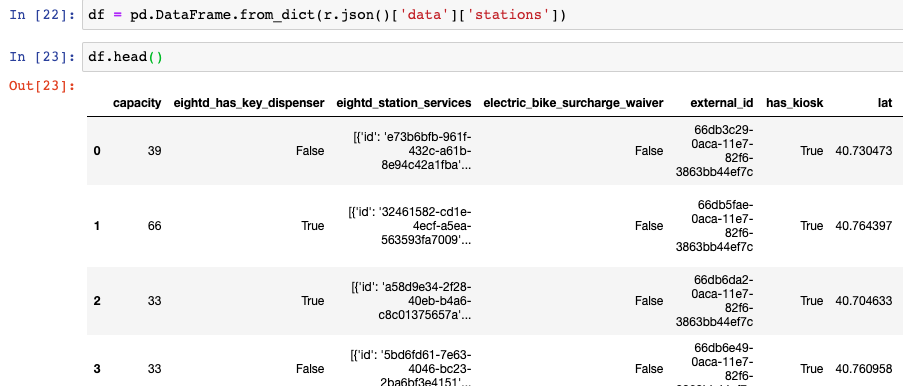
type(r.json())
df = pd.DataFrame.from_dict(r.json()['data']['stations'])Use read_json
The third approach to reading JSON objects into a DataFrame is to use the read_json function in Pandas. A JSON object can be read straight into this function, or as in our case – we can use the URL of a JSON feed as the initial object to read.
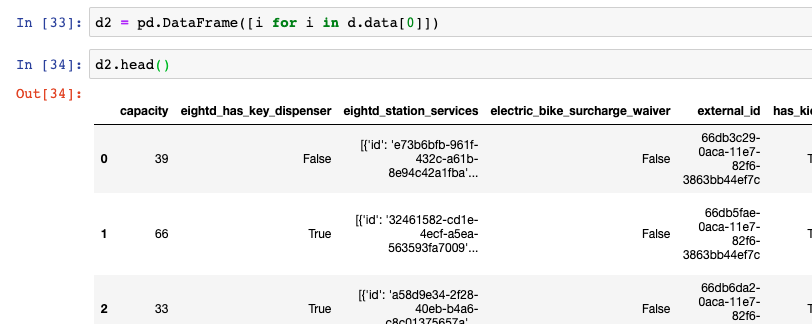
Once the data is stored however, we can see that it is not necessarily at the stations data level that we want to extract (as seen earlier in the tutorial). In order to extract the level of data we want to store in a DataFrame, we must access the series data within our newly created DataFrame (assigned to the value d and create a loop to export all its contents back into our top line DataFrame d2.

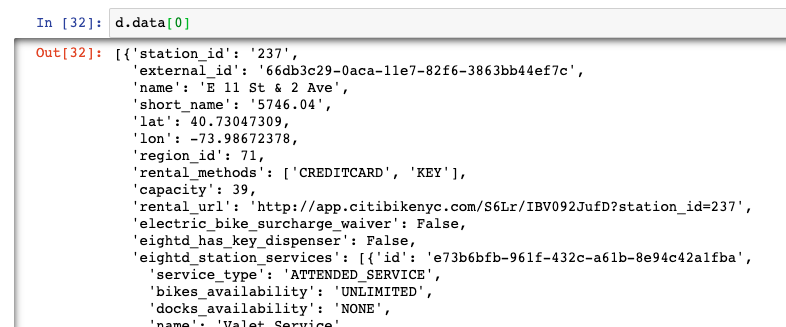
d = pd.read_json("https://gbfs.citibikenyc.com/gbfs/en/station_information.json")
d.data[0]
d2 = pd.DataFrame([i for i in d.data[0]])
d2.head()Summary
json_normalize & read_json are the two critical functions within Pandas to reading JSON data into a DataFrame for further analysis. As you can see from our tutorial, in some instances data does not come into the DataFrame smoothly and requires a bit more unnesting to be at a perfectly columnar level. Solving for that is not in the scope of this article, but some details can be found within the json_normalize documentation using the Union argument.
For the code from this tutorial and screenshots surfaced in the above, please visit our GitHub repository on Data Analysis and the specific Jupyter Notebook for this post, here.
To see further reading about this topic, see the below sources of information:
- This Stack Overflow post on how to accomplish json to dataframe operations
- A post including using Windows UI features to read json
- Long form post performing this transformation using Spotify data