We already know that Python has a tremendous ecosystem of data-centric packages, making it an excellent language for data processing. Pandas is one of these packages, and it makes data import and analysis much easier. We also know that scikit-learn is a very powerful machine learning (ML) library. We can set up different ML models like regression, clustering, classification, etc. In this tutorial, we will learn about working with Pandas and scikit-learn.
In addition to machine learning, scikit-learn has some very useful functions. Here are some of them:
- Label Encoding: This is a straightforward method, and entails turning all values in a particular column to ordered numbers. Take for example a dataset of sports with a column named “sports-types” and values as shown below. There may be more columns in the dataset, but let us concentrate on one categorical column to explain label-encoding.
Let’s encode the text values by creating a running sequence for each of them as seen below:
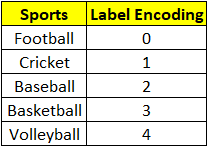
This completes the label encoding of variable sports. That’s all there is to it when it comes to label encoding. Label encoding can present a new challenge depending on the data values and data type because it employs number sequencing. The problem with using numbers is that they introduce a comparison/relationship between them.
There appears to be no correlation between the various sports, although based on the numbers one may believe that “volleyball” has priority over “football”. The algorithm could misapprehend that the data has a hierarchy/order of 0, 1, 2, 3, 4, and assign the game of “football” 4x more weight in the calculation than “volleyball”.
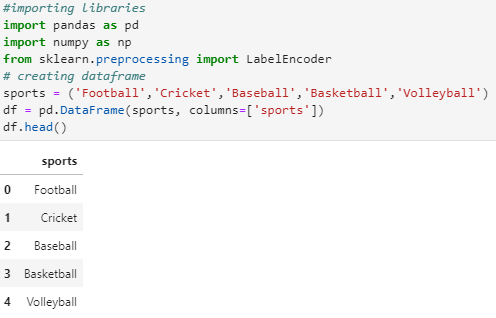
#importing libraries
from sklearn.preprocessing import LabelEncoder
import pandas as pd
import numpy as np
sports = (‘Football’,’Cricket’,’Baseball’,’Basketball’,’Volleyball’)
df = pd.DataFrame(sports, columns=[‘sports’])
df.head()
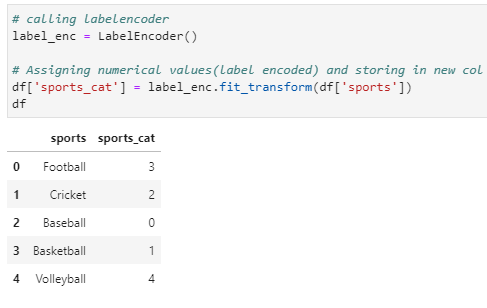
# calling labelencoder
label_enc = LabelEncoder()
# Assigning numerical values(label encoded) and storing in new col
df[‘sports_cat’] = label_enc.fit_transform(df[‘sports’])
df
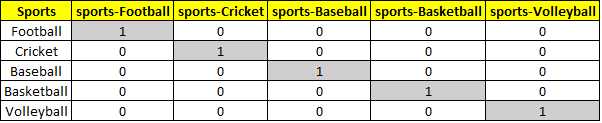
- One-hot Encoding: Though label encoding is straightforward, it suffers from the drawback of causing algorithms to mistake numeric numbers as having some form of hierarchy/order. Another popular alternate strategy known as “One-hot Encoding” addresses this ordering issue. Each category value is turned into a new column with this strategy, and the column is given a 0/1 (false/true) value.
When the sport, “football” is “1”(True), it will indicate football, while all others will be marked as “0” (False).
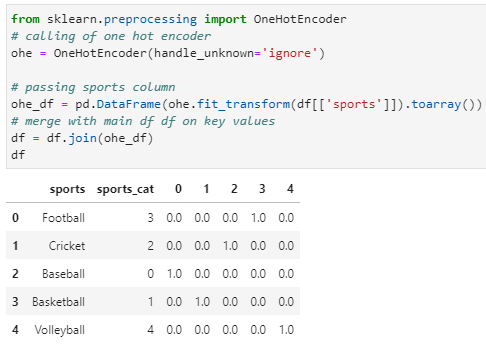
from sklearn.preprocessing import OneHotEncoder
# calling of one-hot-encoder
ohe = OneHotEncoder(handle_unknown=’ignore’)
# passing sports column
ohe_df = pd.DataFrame(ohe.fit_transform(df[[‘sports’]]).toarray())
# merge with main df df on key values
df = df.join(ohe_df)
df
Why is it necessary?
We want to be able to utilize useful categorical data in the model since models only take numerical data as inputs. Regression and classification algorithms will be unable to do so, and we need to convert those columns into 0/1.
This is when one-hot encoding comes in handy. Here’s how it works:
- Use the method to encode categorical integer characteristics.
- The values taken on by categorical (discrete) features should be represented as a matrix of integers as the transformer’s input
- The result will be a sparse matrix, with each column representing one possible value for each characteristic
- Input features are supposed to have values in the range [0, n values]
- Many scikit-learn estimators, especially linear models and SVMs with conventional kernels, require this encoding to feed categorical input
- ColumnTransformer: When all the input variables are of the same type, putting in data transforms like scaling or encoding category variables is simple. When you have a dataset with mixed types and wish to apply data transforms to some but not all the input characteristics, it can be difficult.
Thankfully, the ColumnTransformer in the scikit-learn Python machine learning toolkit allows you to apply data transforms in a selective way to particular columns in your dataset.
So as you have seen in this lesson on working with Pandas and scikit-learn, label encoding and one-hot encoding will be combined into a single line of code by ColumnTransformer. And the result is the same.
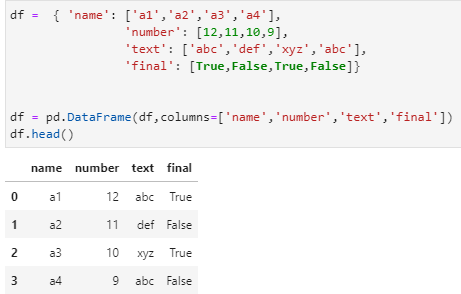
df = { ‘name’: [‘a1′,’a2′,’a3′,’a4’],
‘number’: [12,11,10,9],
‘text’: [‘abc’,’def’,’xyz’,’abc’],
‘final’: [True,False,True,False]}
df = pd.DataFrame(df,columns=[‘name’,’number’,’text’,’final’])
df.head()
The first column looks categorical. To encode this, we may use one-hot encoder, but here we are going to use column transformers. So, continuing with our lesson on working with Pandas and scikit-learn…..
(This data is for practice purpose only.)
We are going to use two arguments out of the many under ColumnTransformers.
The 1st one is a list of “tuples” (used to store multiple items in a single variable) in an array called transformers. The array’s items are listed in the following order:
- Name : ColumnTransformer’s name
- Transformer: Here, we provide an estimator
- Columns : A list of columns that needs to be transformed
The remainder is the second argument. This instructs the transformer on how to handle the remaining columns in the DataFrame. By default, the transformer returns only the columns that have been transformed, while the rest of the columns are eliminated. We can, however, direct the transformer on what action to take on the rest of the columns. These can either be dropped, passed through unaltered, or you can apply another estimator.
Example:

from sklearn.preprocessing import OneHotEncoder
from sklearn.compose import ColumnTransformer
CT = ColumnTransformer([(‘first’, OneHotEncoder(), [0])], remainder=’passthrough’)
As you can see from the sample above, we’ll just call the transformer “first.” As the estimator, we’re using the one-hot encoder() function Object() { [native code] } to create a new instance. Then, we will specify that only the first column (we can add more columns later) will be transformed. We are also passing remainder as pass through so the rest of the columns are processed unaltered.
Following the creation of the CT object, we must fit along with the transformation of the DataFrame in order to one-hot encode the column. To accomplish the same, we can use query as shown below:


new_arr = np.array(CT.fit_transform(df), dtype = np.str)
new_arr
We can pass multiple columns as shown below:
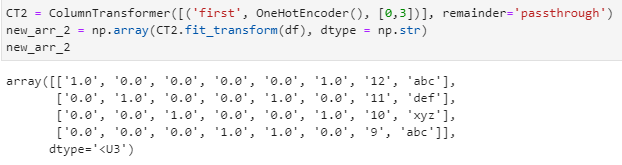
CT2 = ColumnTransformer([(‘first’, OneHotEncoder(), [0,3])], remainder=’passthrough’)
new_arr_2 = np.array(CT2.fit_transform(df), dtype = np.str)
new_arr_2
Summary
In this chapter on working with Pandas and scikit-learn, we have seen that each strategy has its own advantages and disadvantages, so it is important to understand the many options for encoding categorical variables. This is also one of the critical stages in data science, so bear that in mind when working with categorical variables. Here’s when to use one-hot encoding, label encoding and ColumnTransformer:
- We apply one-hot encoding:
- When categorical features are not ordinal
- When there are fewer categorical features
- We apply label encoding:
- When categorical features are ordinal
- When categories are large in numbers
- We apply ColumnTransformer:
- When columns are of different types
- When we want to apply different transformation to different features
References
- Official Documentation for one-hot encoder
- Official Documentation for label encoder
- Official Documentation for ColumnTransformer
- Jupyter Book Online