Python is a general purpose programming language often used in data analysis, and is well liked in the developers’ community because of its uncomplicated ecosystem of data-centric packages. One of these packages is the open-source Pandas, and it greatly simplifies data import and analysis. It was developed by American software developer Wes McKinney. In this article we are going to look at how to manipulate specific values in a pandas DataFrame.
According to the library’s website, Pandas is a “fast, powerful, flexible, and easy to use open-source tool built on top of the Python programming language”. Pandas is an acronym that stands for Python Data Analysis Library. Wikipedia describes it as “the name derived from the term “panel data”. (Do note: pandas is usually written in all lowercase letters, although it’s considered best practice to capitalize the first letter at the start of a sentence.)
Pandas Dataframe is a two-dimensional labeled data structure, and comprises three main parts – data, rows, and columns. Pandas is used to mainly perform operations like merging, reshaping, aggregation, splitting and selection.
In a pandas DataFrame, there are multiple methods to fetch the data, based on two types of indexing:
- Location-based
- Label-based
Location-based Indexing
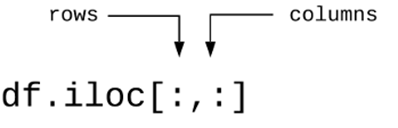
By using .iloc and providing the row and column collection as ranges, you can filter pandas DataFrames using location-based indexing. The first value is included in the provided range, but not the second.
This means that you must select the first index using the range [0:1], so your selection starts at [0] but does not include [1]. (the second index). Example: you can select the first row and column of a pandas DataFrame by providing the range [0:1] for the row selection and the range [0:1] for the column selection.
Using the index values assigned to it, we can obtain a specific value from a row and column using the iloc() function. Keep in mind that the iloc() function only accepts integer type values as index values for the values to be accessed and displayed.
I’m using Jupyter book online which can run in your browser.
Let’s use the inbuilt data set (big.csv) and see an example.
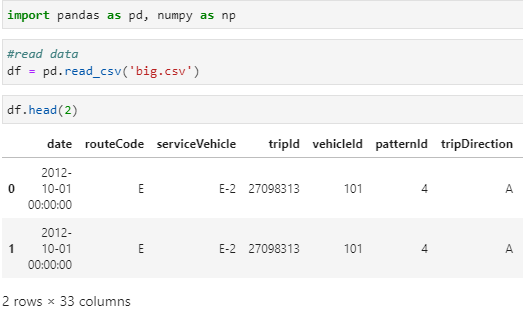
import pandas as pd, numpy as np
#read data
df = pd.read_csv(‘big.csv’)
#display data
df.head(2)
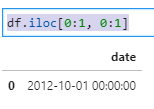
df.iloc[0:1, 0:1]
Label-based Indexing
Label-based indexing can be used to query a pandas DataFrame.
This function of a pandas DataFrame is of high value as you can build an index using a specific column, (meaning: a label) that you want to use for managing and querying your data.
For example, one can develop an index from a column of values and then use the attribute.loc to select data from pandas DataFrame based on a value found in the index.
The loc property is used to ingress a set of rows and columns using label(s) or a Boolean list.
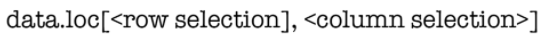
There are many ways to use loc and its very useful as depicted below:
- Passing a single index:
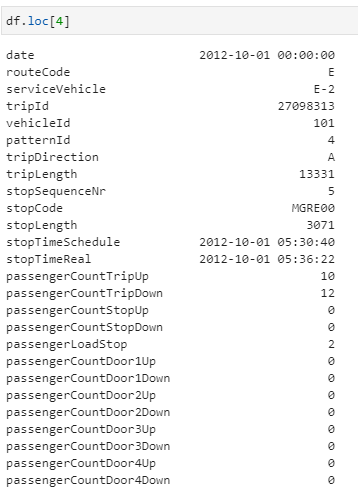
df.loc[4]
- Passing the column label:
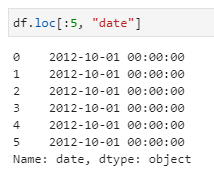
df.loc[:5, “date”]
- Slice-ability on row and column index names:
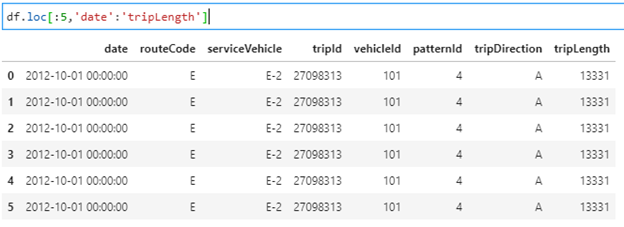
df.loc[:5,’date’:’tripLength’]
- Pass lists with row or column index names:
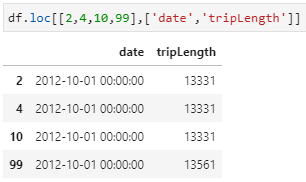
df.loc[[2,4,10,99],[‘date’,’tripLength’]]
- Boolean lists:
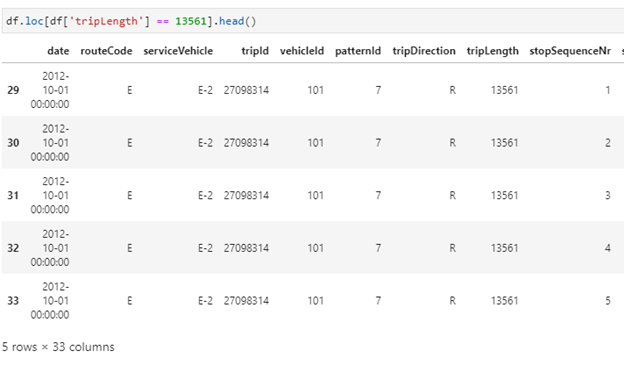
df.loc[df[‘tripLength’] == 13561].head()
We can try all sorts of possibilities here like triplength > 14000
Or triplength greater than 13000 but less than 13200.
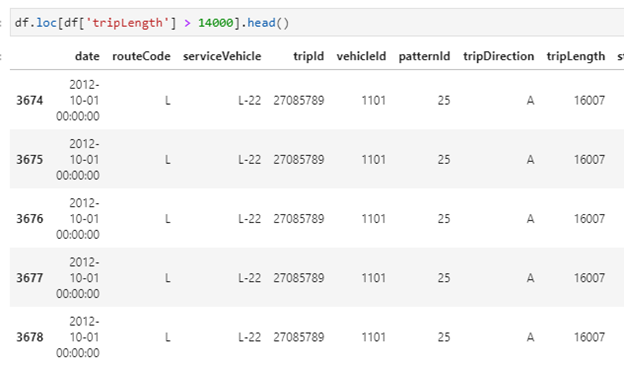
df.loc[df[‘tripLength’] > 14000].head()
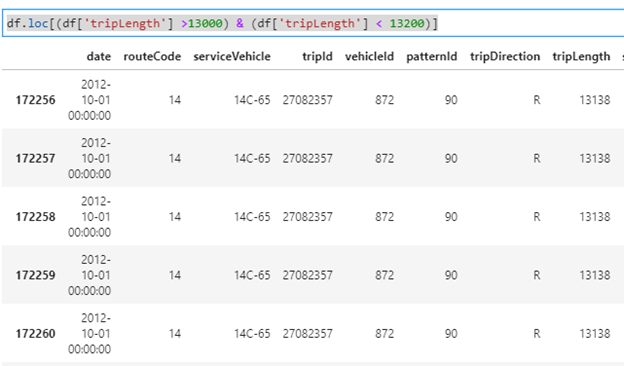
df.loc[(df[‘tripLength’] >13000) & (df[‘tripLength’] < 13200)]
These are a few examples on how loc can be used.
The primary distinction between the two approaches is as follows:
- loc retrieves rows (and/or columns) with specific labels.
- iloc returns rows (and/or columns) at integer locations.
Apart from the .loc and .iloc method, there are other ways to fetch data from a pandas DataFrame :
- Pandas DataFrame.at[ ]
Pandas at[] returns data in a DataFrame at the specified location. The passed position has the following format: [poition, Column Name]. This approach is similar to Pandas loc[ ], but at[ ] is used to return only a single value and so works faster.
This method is faster than the.loc[] method since it only deals for single values.
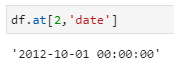
df.at[2,’date’]
- Pandas DataFrame.iat[ ]
Pandas’ iat[] method returns data in a DataFrame at the passed location. The passed location is in the format [row position, column position]. This method is similar to Pandas iloc[], but iat[] is used to return only one value and thus works faster.
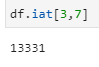
df.iat[3,7]
- Pandas DataFrame.ix[ ]
Pandas DataFrame.ix[ ] is a slicing method that uses both labels and integers. Pandas offers a hybrid method for selections and subsetting the object using the ix[] operator in addition to pure label-based and integer-based methods. ix[] is the most general indexer, accepting all of the loc[] and iloc[] inputs.
This function is removed now as per official documentation.
Let’s sum up the differences in all the methods:
- loc: work on index only
- iloc: work on position
- at: get scalar values. It’s a very fast loc (single element in the DataFrame)
- iat: Get scalar values. It’s a very fast iloc (single element in the DataFrame)
Let’s now focus on some scenarios we may face while doing data analytics:
- Get a value from a cell of a DataFrame:
To select a single value, the fastest way is to use .iat, although there are multiple ways to do it as shown:
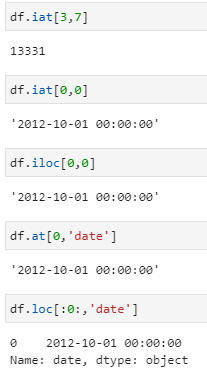
Only .loc returns the index as well but all other functions have resulted into single cell value.
df.iat[3,7]
df.iloc[0,0]
df.at[0,’date’]
df.loc[:0:,’date’]
- Input a particular value in a cell of DataFrame:
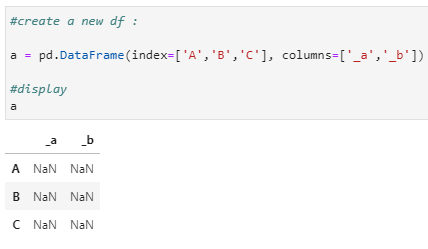
#create a new df :
a = pd.DataFrame(index=[‘A’,’B’,’C’], columns =[‘_a’,’_b’])
#display
a
There are multiple ways to solve this using functions explained above:
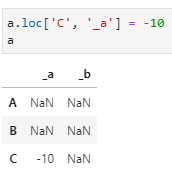
a.loc[‘C’, ‘_a’] = -10
a
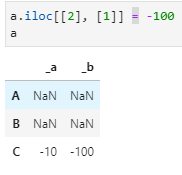
a.iloc[[2], [1]] = -100
a
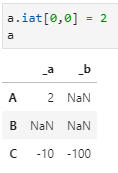
a.iat[0,0] = 2
a

a.at[‘A’,’_b’] = 2
a
Summary
Real-world data is often messy or in the wrong format. One of the first and most important tasks for data scientists/analysts is to clean and manipulate this raw data. To complete this task, it is important to know a versatile method for accessing rows and columns. Here, the loc, iloc, at and iat methods are just what the doctor ordered.
To summarize: loc[] and iloc[] both have the ability to pick specific data points from a DataFrame. Depending on your use case, you can use the appropriate one.
The loc function is label-based, and the following inputs are permitted:
- A single/list of label ‘A’ or 1 (1 is interpreted as index)
- A slice with the letters ‘A’ through ‘Z’ written on it (both ends are included)
- Conditions, a Boolean series, or a Boolean array
- Single argument callable function
iloc operates on integer positions and accepts the following inputs:
- An integer/list of array, such as 1/[1,2]
- A slice with the ratio 1:7 (the endpoint 7 is not included)
- Conditions, only a Boolean array is accepted
- Single argument callable function
References
- Pandas official website
- Jupyter book
- Pandas Official documentation for .loc.
- Pandas Official documentation for .iloc.
- Pandas Official documentation for .at.
- Pandas Official documentation for .iat.