Dictionaries and Lists are commonly used objects within Python and often need to be converted into Pandas Dataframe objects. Before jumping onto a little complex topic, let’s discuss some basics.
What is Pandas?
Pandas is Python’s most popular open-source data manipulation library and Python Data Analysis Library is the name of this library. It is built on top of the NumPy kit. DataFrames are the most commonly used data structures in Python, allowing to handle and store data from tables by performing row and column manipulations. Pandas is extremely useful for data merging, reshaping, aggregation, splitting, and selection.
What are Lists?
In Python, a list is a data structure that is a mutable (or changeable) ordered sequence of elements. A list’s items are the elements or values that make up the list. Lists are characterized by values between square brackets [ ], just as strings are defined by characters between quotes.
When working with a large number of similar values, lists come in handy. They allow you to keep data that belongs together in one place, condense your code, and perform the same methods and operations on multiple values at the same time.
Consider all of the various collections you have on your computer while speaking about Python lists and other data structures that are forms of collections: your files, your song playlists, your browser bookmarks, your emails, the collection of videos you can watch on a streaming site, and so on.
Basic List Operations
Let’s get started by creating a list with items of the string data type:

countries = [‘india’, ‘usa’, ‘uk’, ‘brazil’]
When we print this list, it appears exactly as it did when we first created it:
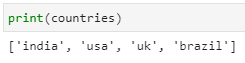
print(countries)
Each item in a list can be called individually using indexing because it is an ordered sequence of elements. Lists are a flexible data type that can have values added, removed, and changed because they are made up of smaller parts.
In this article, we’ll look at a few different ways to work with lists in Python.
Indexing Lists
Starting with the index number 0, each item in a list corresponds to an index number, which is an integer value.
The index breakdown for the list countries is as follows:

We can access and manipulate lists in the same way we do other sequential data types because each item in a Python list has a corresponding index number.
We can now refer to a discrete item of the list by its index number:
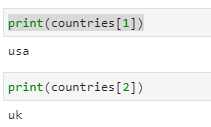
print(countries[1])
print(countries[2])
If we call an element greater than 3, it will be out of range and not valid:
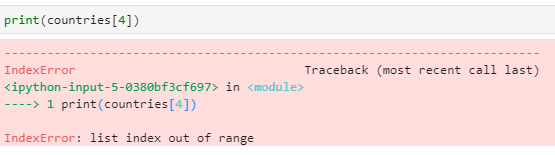
print(countries[4])
The negative index breakdown for the same list countries looks like this:

We can also refer to a discrete item of the list by its negative index number:
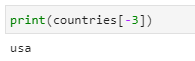
print(countries[-3])
Concatenate Using a List
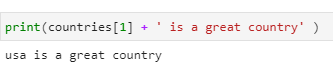
print(countries[1] + ‘ is a great country’ )
Modifying A List
If we want to change the string value of the item at index 0 from 'india’ to argentina', we can do as follows:
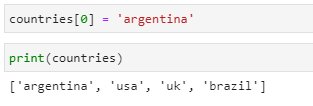
countries[0] = ‘argentina’
print(countries)
Slicing a list
A few items from the list can also be highlighted. If we just want to print the middle things from countries, we can do that by making a slice. By generating a set of index numbers separated by a colon [x:y], we can call multiple values with slices:
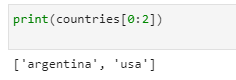
print(countries[0:2])
If we want to print first three elements of the list:
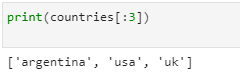
print(countries[:3])
We can access list using negative index like below:
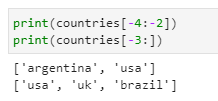
print(countries[-4:-2])
print(countries[-3:])
What Are dictionaries?
Python’s built-in mapping type is the dictionary. In Python, dictionaries map keys to values, and these key-value pairs are a convenient way to store data.
Dictionaries are constructed with curly braces on either side and are typically used to hold data that is related, such as the information contained in an ID or a user profile.
Example of a dictionary:

games = {‘sport’: ‘football’, ‘player’: ‘Ronaldo’, ‘goals’: 700}
print(games)
The words to the left of the colons are the keys. They can be made up of any immutable data type. The keys in the dictionary above are:
- sport
- player
- goals
The words to the right of the colons are the values. Values can be of any data type. The values in the dictionary above are:
- football
- player
- 700
Accessing Data Items with Keys
Because dictionaries offer key-value pairs for storing data, they can be important elements in Python program.
If we want to access sport from dictionary, this is how it can be done:
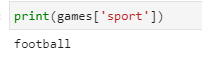
print(games[‘sport’])
Using Methods to Access Elements
In addition to using keys to access values, we can use some built-in methods:
- dict.keys() isolates keys
- dict.values() isolates values
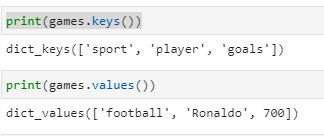
print(games.keys())
print(games.values())
Adding and Changing Dictionary Element
We can add key-value pairs to dictionaries by using the following syntax:

games[‘assist’] = ‘400’
print(games)
Deleting Dictionary Elements
Just as we can add key-pair in the dictionary, we can delete as well as shown below:
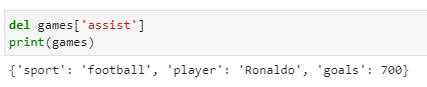
del games[‘assist’]
print(games)
What is a Pandas DataFrame?
DataFrame is a two-dimensional labelled data structure with columns that can be of various types. Consider it similar to a spreadsheet, SQL table, or dict of Series objects. It is the most frequently used pandas object. DataFrame, like Series, accepts a wide range of input:
- Dict of 1D ndarrays, lists, dicts, or Series
- 2-D numpy.ndarray
- Structured or record ndarray
- A Series
- Another DataFrame
You can optionally pass index (row labels) and columns (column labels) arguments along with the data. If you pass an index and/or columns, the index and/or columns of the resulting DataFrame is guaranteed. As a result, a dict of Series plus a particular index would discard any data that does not fit the passed index.
Creating a DataFrame using List
DataFrame can be created using a single list or a list of lists.
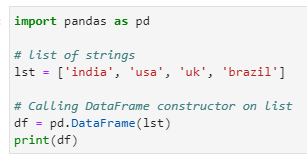
import pandas as pd
# list of strings
lst = [‘india’,’usa’,’uk’,’brazil’]
# Calling DataFrame constructor on list
df = pd.DataFrame(lst)
print(df)
Output:

Creating DataFrame from a Dictionary of ndarray/lists
To make a DataFrame out of a dict of narrays/lists, each narray must be the same length. If index is specified, the length index must match the length of the arrays. If no index is defined, index is set to range(n), where n is the array length.
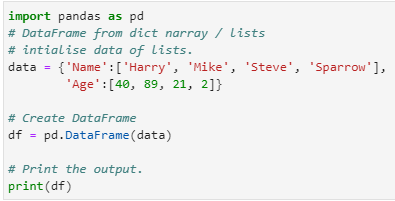
import pandas as pd
# DataFrame from dict narray / lists
# initialise data of lists.
data = {‘Name’ : [‘Harry’, ‘Mike’, ‘Steve’, ‘Sparrow’],
‘Age’ : [40,89,21,2]}
# Create DataFrame
df = pd.DataFrame(data)
# Print the output.
print(df)
Output:
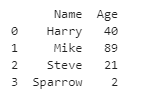
A DataFrame is a two-dimensional data structure in which data is organized in rows and columns in a tabular format. On rows and columns, we can perform basic operations such as choosing, removing, inserting, and renaming.
Column Selection: In order to select a column in Pandas DataFrame, we can either access the columns by calling them by their column’s name.
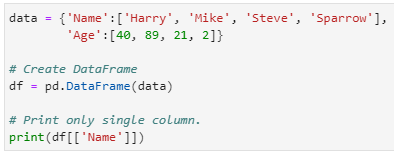
data = {‘Name’ : [‘Harry’, ‘Mike’, ‘Steve’, ‘Sparrow’],
‘Age’ : [40,89,21,2]}
# Create DataFrame
df = pd.DataFrame(data)
#Print only single column.
print(df[[‘Name’]])
Output:
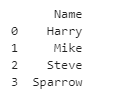
Row Selection: Pandas has a one-of-a-kind way of retrieving rows from a DataFrame. To retrieve rows from a Pandas DataFrame, use the loc[] process.
data = {‘Name’ : [‘Harry’, ‘Mike’, ‘Steve’, ‘Sparrow’],
‘Age’ : [40,89,21,2]}
# Create DataFrame
df = pd.DataFrame(data)
# retrieving row using loc
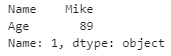
first = df.loc[1]
print(first)
Output:
You can retrieve multiple rows as well by defining index before or after colon ( : )
data = {‘Name’ : [‘Harry’, ‘Mike’, ‘Steve’, ‘Sparrow’],
‘Age’ : [40,89,21,2]}
# Create DataFrame
df = pd.DataFrame(data)
# retrieving multiple row using loc
first = df.loc[:]
print(first)
Output:
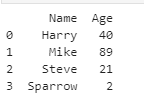
Another Example:
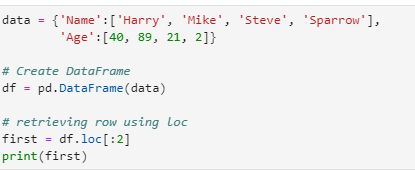
data = {‘Name’ : [‘Harry’, ‘Mike’, ‘Steve’, ‘Sparrow’],
‘Age’ : [40,89,21,2]}
# Create DataFrame
df = pd.DataFrame(data)
# retrieving row using loc
first = df.loc[:2]
print(first)
Output:
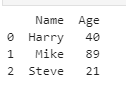
Now, let’s move to a little more complex yet easy DataFrame conversion:
Create list from Pandas DataFrame
Let’s say we have an existing pandas df:
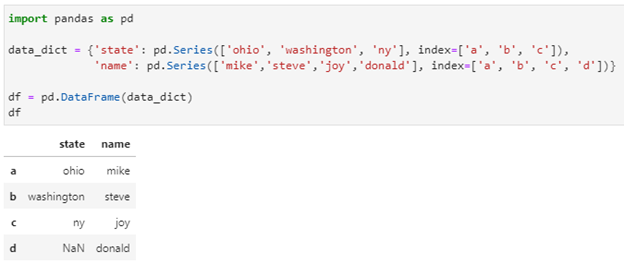
data_dict = {‘state’: pd.Series([‘ohio’, ‘washington’, ‘ny’], index=[‘a’, ‘b’, ‘c’]),
‘name’: pd.Series([‘mike’,’steve’,’joy’,’donald’], index=[‘a’, ‘b’, ‘c’, ‘d’])}
df = pd.DataFrame(data_dict)
df
We can fetch state or name as a list as using tolist() function:
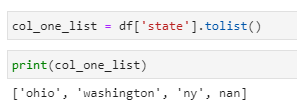
col_one_list = df[‘state’].tolist()
print(col_one_list)
You can also convert it to numpy array:
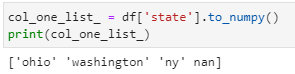
col_one_list_ = df[‘state’].to_numpy()
print(col_one_list_)
Fetch a list from DataFrame for a particular data type
In the following DataFrame, we have two types of data that we can check using dtypes:
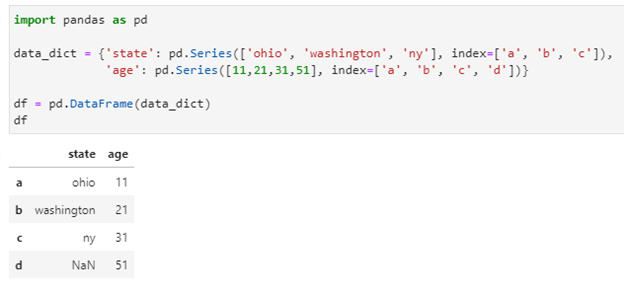
import pandas as pd
data_dict = {‘state’: pd.Series([‘ohio’, ‘washington’, ‘ny’], index=[‘a’, ‘b’, ‘c’]),
‘age’: pd.Series([11,21,31,51], index=[‘a’, ‘b’, ‘c’, ‘d’])}
df = pd.DataFrame(data_dict)
df
Using dtypes:
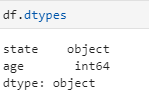
df.dtypes
Now we can fetch columns which are only int data type:
Step 1 is to fetch int type columns.
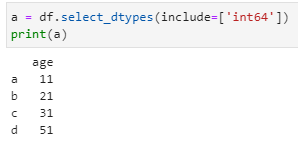
a = df.select_dtypes(include=[‘int64’])
print(a)
Step 2 is to convert them into lists.
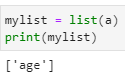
mylist = list(a)
print(mylist)
If there are multiple int type columns in the DataFrame, it will create a list for all of them.
Convert list of dictionaries to a Pandas DataFrame
Suppose you have a dictionary as shown below:

dict_= [
{‘points’: 50, ‘year’: 1990, ‘sport’ : ‘football’},
{‘points’: 25, ‘month’: “february”},
{‘points’:90, ‘month’: ‘january’},
{‘points’:20, ‘month’: ‘june’, ‘sport’ : ‘baseball’}]
print(dict_)
Conversion of dict into a DataFrame is relatively simple:
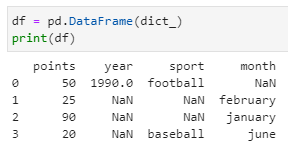
df = pd.DataFrame(dict_)
print(df)
Create DataFrame from multiple list:
Suppose you have three lists as defined:
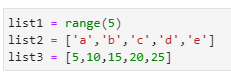
list1 = range(5)
list2 = [‘a’,’b’,’c’,’d’,’e’]
list3 = [5,10,15,20,25]
We can use these lists to create one single DataFrame as below:
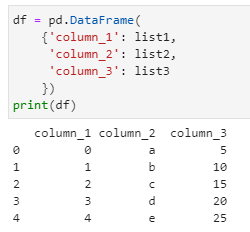
df = pd.DataFrame(
{‘column_1’: list1,
‘column_2’: list2,
‘column_3’: list3
})
print(df)
Read list of lists into DataFrame
A list of lists in Python is a list object where each list element is a list by itself.
For example, we have a list of lists as defined below:

lst_of_lst= [[‘name’, ‘age’], [‘mike’ , 21], [‘steve’,32]]
We can convert that into Pandas DataFrame as follows:
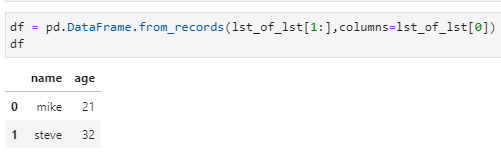
df = pd.DataFrame.from_records(lst_of_lst[1:],columns=lst_of_lst[0])
df
In this example, we have used indexing. Let’s see the breakdown:
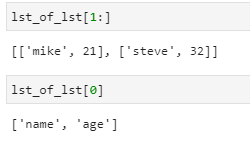
lst_of_lst[1:]
lst_of_lst[0]
We are reading columns as name and age along with records under the same headers starting from index.
Summary
Most Pandas users easily learn how to import data from spreadsheets, CSV files, and SQL databases. However, there are occasions when you want to populate a DataFrame with data from a simple list or dictionary. Pandas provides several choices, but it’s not always clear when to use one of them.
There is no ‘best’ approach; it all depends on your requirements. I prefer list-based approaches because I am usually concerned with order, and lists ensure that I maintain that order. The most important thing is to be conscious of the choices available so that you can select the simplest choice for your situation.
These samples can appear simple on the surface, but I find that I often use them to produce fast snippets of information that can supplement or explain a more complex study. The positive thing about data in a DataFrame is that it’s simple to convert it to other formats like Excel, CSV, HTML, and so on. This versatility comes in handy when creating ad-hoc analysis and reporting.