Before we launch into what is column encoding in scikit-learn, label encoding and stuff like that, let us first understand why encoding is needed.
What Is Categorical Encoding?
Any organized dataset will often include numerous columns, each of which contains a mix of numerical and category variables. Only numbers can be understood by a machine. It is unable to comprehend text. That holds true for machine learning (ML) algorithms as well. That is why we must transform categorical columns to numerical columns so that the ML algorithm can interpret them. “Categorical Encoding” is the term for this method.
How Should We Handle Categorical Variables?
Before we launch into what is column encoding in scikit-learn, let’s learn about the 2 most used techniques to handle categorical variables:
- Label encoding
- One-hot encoding
In this article, we are going to focus on label encoding and how it works.
What Is Label Encoding?
Label encoding is a well-known encoding method for categorical variables. In this technique, each label is given a unique integer based on alphabetical order.
Consider a dataset df with a column named “country”. Though there will be many more columns in the dataset, we will simply focus on one categorical column to explain label-encoding.
Let’s look at how to use the scikit-learn module to create label encoding in Python.
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
#create df
country = (‘usa’,’uk’,’india’,’mexico’,’brazil’,’thailand’,’russia’)
df = pd.DataFrame(country, columns=[‘country’])

# creating instance of labelencoder
label_encoder = LabelEncoder()

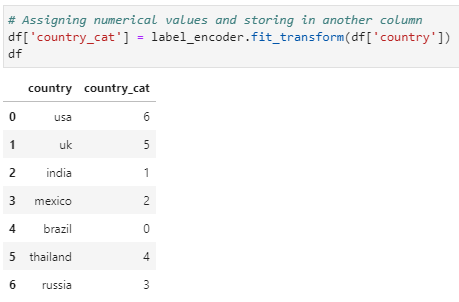
# Assigning numerical values and storing in another column
df[‘country_cat’] = label_encoder.fit_transform(df[‘country’])
df
There’s one more way to do it:
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
#create df
country = (‘usa’,’uk’,’india’,’mexico’,’brazil’,’thailand’,’russia’)
df = pd.DataFrame(country, columns=[‘country’])

# converting column type to category
df[‘country’] = df[‘country’].astype(‘category’)

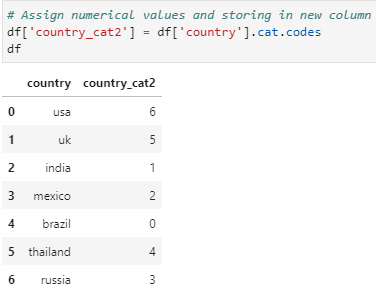
# Assign numerical values and storing in new column
df[‘country_cat2’] = df[‘country’].cat.codes
df
Challenges With Label Encoding
The country names in the scenario above have no order or rank. When label encoding is used, however, alphabets are used to rank the nation names. As a result, there’s a good chance the model will capture the interaction between India, Thailand, UK, and the US (which isn’t the case).
This is something that we do not want to happen. So, how can we get past this stumbling block? This is where the concept of “One-hot Encoding” comes into play.
What Is One-hot Encoding?
Label encoding seems straightforward, but it causes algorithms to incorrectly interpret numeric numbers as being ordered or hierarchical. This ordering problem can be addressed via one-hot encoding, another popular alternative strategy. With this strategy, each category value is turned into a new column, and each column is given a 1 or 0 (true or false) value.
Let’s implement one-hot encoding using scikit-learn.
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
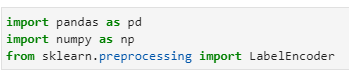
#create df
country = (‘usa’,’uk’,’india’,’mexico’,’brazil’,’thailand’,’russia’)
df = pd.DataFrame(country, columns=[‘country’])

# passing coutry column
ohc_df = pd.DataFrame(ohc.fit_transform(df[[‘country’]]).toarray())

# merge with main df
df = df.join(ohc_df)
df

You can also use dummy value approach as shown below:
import pandas as pd
import numpy as np
from sklearn.preprocessing import LabelEncoder
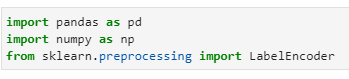
#create df
country = (‘usa’,’uk’,’india’,’mexico’,’brazil’,’thailand’,’russia’)
df = pd.DataFrame(country, columns=[‘country’])

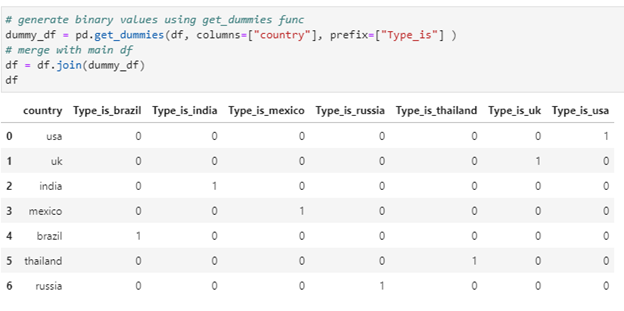
# generate binary values using get_dummies func
dummy_df = pd.get_dummies(df, columns=[“country”], prefix=[“Type_is”] )
# merge with main df
df = df.join(dummy_df)
df
Challenges with One-hot Encoding
One-hot encoding introduces multi-collinearity in the dataset. In machine learning models, multi-collinearity is a severe problem. The “Variance Inflation Factor” is a standard approach to assess for multi-collinearity.
Summary
Because each strategy has its own set of advantages and disadvantages, it is critical to understand the many options for encoding categorical variables. It is a critical stage in data science; thus, we advise you to keep these notions in mind when working with categorical variables.