Datasets often come with extra data that for analysis purposes are not required, are unwanted, or are simply going to be dropped from the analysis at a later point as they’re irrelevant. Pandas provides several methods of deleting or eliminating those columns from a DataFrame as well as methods of simply selecting-out the columns one wants to analyze. Similar to selecting data using conditionals, Pandas provides SQL-like operations to help us select and manipulate data, mirroring the SELECT statement in SQL.
In this tutorial, we will show how to select DataFrame columns using several different types of functions including the following:
- Selection by column name or index using DataFrame[columns]
- Loading data into a new DataFrame object using DataFrame()
- Using iloc to select columns using their index number or multiple columns by a list of indexes
Loading Data For Analysis
Firstly we will load data from an open-source data set to perform our functions on from FSU.

import pandas as pd
file_name = "https://people.sc.fsu.edu/~jburkardt/data/csv/homes.csv"
df = pd.read_csv(file_name)Dataset Contents
Once the file is loaded into the df variable for a DataFrame, we can begin analyzing the data in the columns. We can explore the data through df.head() and df.describe() functions to examine the data as it exists in the complete DataFrame however, in this case, we will take the simple approach of looking at the top several rows of data using the head() function.

The function DataFrame.columns lists out all the current columns within the DataFrame object. We see there are nine columns that can be selected in our existing DataFrame contents and the names of those columns can be seen below:

df.head()
df.columnsNow that we understand the contents of our DataFrame we can go on to the meat of our content, selecting columns using two separate approaches.
Selecting Using DataFrame[columns]
The most common method of column selection is to put a list of the column names within the df[[]] function to access the column object in our DataFrame. This will return a DataFrame object with only the selected columns within it. This is by far the simplest approach to selecting the columns in Pandas.
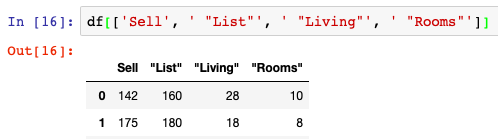
df[['Sell', ' "List"', ' "Living"', ' "Rooms"']]We see the results of this approach listed above with only the four selected columns being reflected in our output of data. In order to save this data into a new DataFrame, we would simply have to assign it to a different variable name such as df_new.
Selecting Using DataFrame()
Another approach is to restate the DataFrame object using pandas.DataFrame. Just as we can read in list, dictionary, and other types of data using DataFrame() we can also read in the contents of other DataFrames. Feeding in the original DataFrame and the specific columns you want to select in list format works similar to the below:
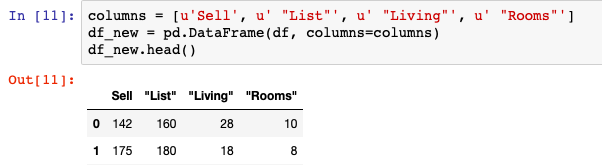
columns = [u'Sell', u' "List"', u' "Living"', u' "Rooms"']
df_new = pd.DataFrame(df, columns=columns)
df_new.head()iloc
DataFrame.iloc can also be used to select columns in a DataFrame. By constructing an index of the columns that need to be excluded, those right of the 4th column, we can reassign the variable to another DataFrame. This new object will contain only those columns not originally filtered out using the [:,0:4] approach.
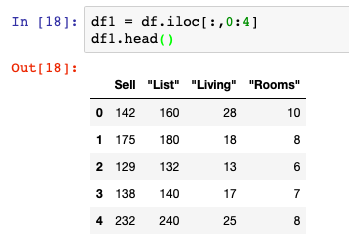
df1 = df.iloc[:,0:4]For iloc to work – you have to understand that it takes in both row and column data to function. The arguments, or row and column data, can be passed in on each side of the function: .iloc[rows, columns]. One note here is that we must define the row and column values by integer and list formats.
Other examples of how iloc can select columns are below:

#returns the 4th column of the DataFrame with the header name
df.iloc[:,[3]]
#returns the 4th column of the DataFrame without the header name
df.iloc[:,3]Additionally, we can provide in longer list values to select columns if needed, similar to our first example which include the following:

df.iloc[:,[1,2,4]]We can also use list generating functions to construct our list, nested within the iloc function, such as the Python Standard Library’s range() function.
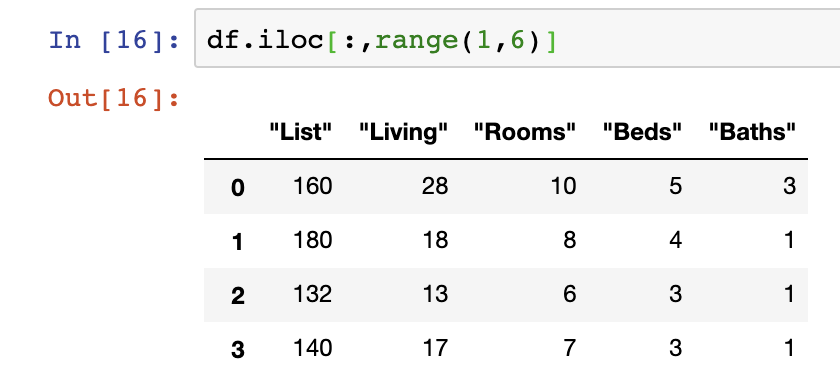
df.iloc[:,range(1,6)]While we’ve only covered this approach in selecting columns, we can similarly use the iloc function to select row values – something which we’re not going to get into for obvious reasons in this post.
DataFrame.drop()
The first three examples focused on explicitly selecting data however, DataFrame.drop() can be used to eliminate nonrelevant columns.

Summary
We’ve covered four distinct methods of selecting columns using various methods including:
- Directly selecting the columns using DataFrame[[]]
- Selecting using DataFrame(data, columns=columns)
- iloc on single and multiple column indexes
- Dropping unwanted columns using .drop()
Additional sources of content on this topic, some of which veer from our selection of multiple columns, include the following:
- Tips for Selecting Columns – Practical Business Python
- Selecting columns using Column Names – Kite.com
- Selecting multiple columns in a pandas dataframe – Stack Overflow
For more on how to use Indexing and Selecting data from the official Pandas documentation, please see the following link. More information on common Pandas operations can be found in our detailed tutorials and on our GitHub.