This article contains affiliate links. For more, please read the T&Cs.
One common operation in Pandas and data analysis generally is to rename the columns in the DataFrame you are working on. There are actually several varying options on how to perform renaming columns in Pandas. None of the options offer a particularly enhanced performance within Pandas for speed as measured by CProfile.
The operations cover a wide degree of complexity as some columns may require significant cleanup in string format, for instance, removing extra characters, replacing string values, or performing matching arguments using RegEx expressions.
Loading Data
This tutorial covers several of these using Jupyter Notebook examples of how the operations can be performed. The below uses publicly available data from FSU to run through each operation as shown in the DataFrame below:
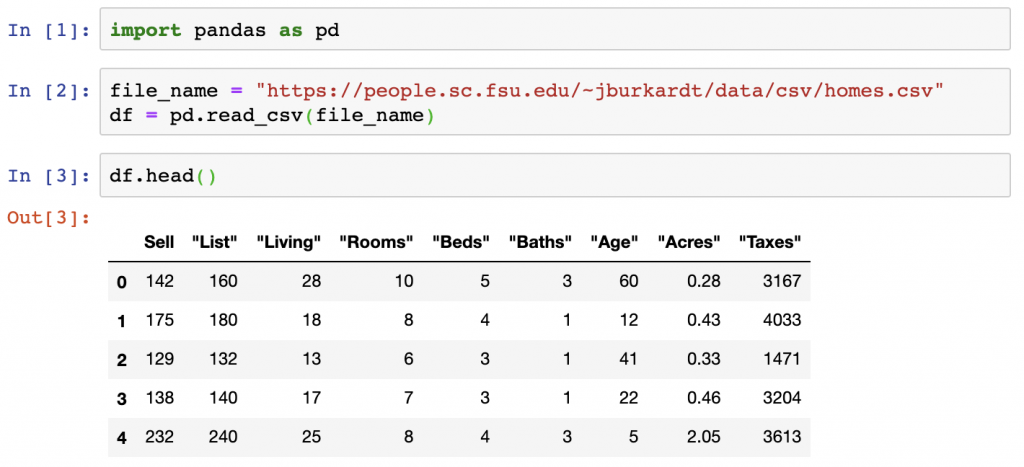
import pandas as pd
file_name = "https://people.sc.fsu.edu/~jburkardt/data/csv/homes.csv"
df = pd.read_csv(file_name)
df.head()Renaming Columns
In the screenshot above, there are 9 columns in the DataFrame. Next, a new method of renaming the individual column and all columns at once is covered. In this case, we only updated each string to remove the additional ” at the end of the 8 columns. We want to rename those columns so that those extra pieces of data are removed. We do so by looping through the column names using a lambda function on our columns and using the replace() function from the Python Standard Library to update each string within the Pandas columns object.
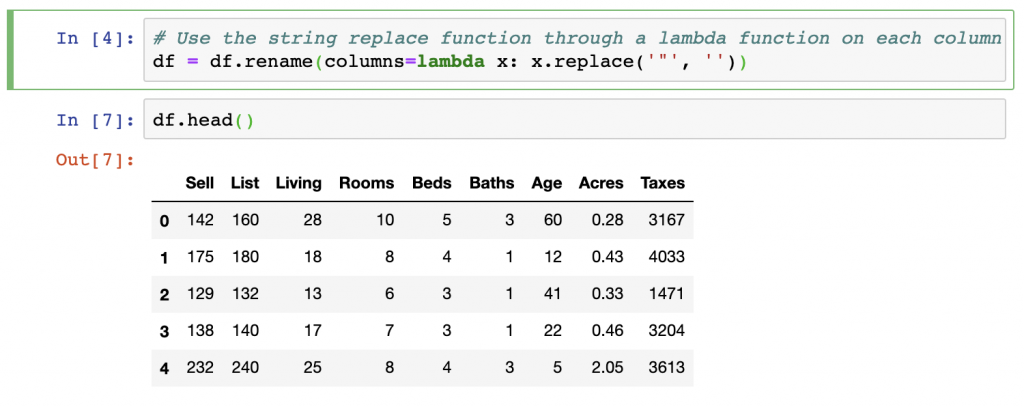
# Use the string replace function through a lambda function on each column
df = df.rename(columns=lambda x: x.replace('"', ''))
df.head()Another approach is to overwrite the DataFrame’s columns variable seen as df.columns with a list of the column names. This is done in string format on the columns that we want to overwrite.
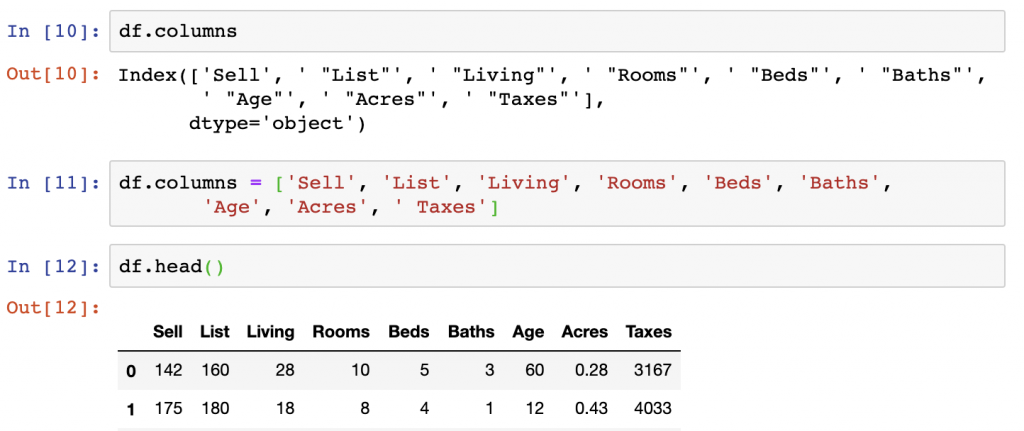
df.columns
df.columns = ['Sell', 'List', 'Living', 'Rooms', 'Beds', 'Baths',
'Age', 'Acres', ' Taxes']
df.head()The last approach we’ll try today is really just a functional version of the manual column list approach directly above this one. We will overwrite the column names with a list generated by a loop that removes the parts of the names we don’t want.
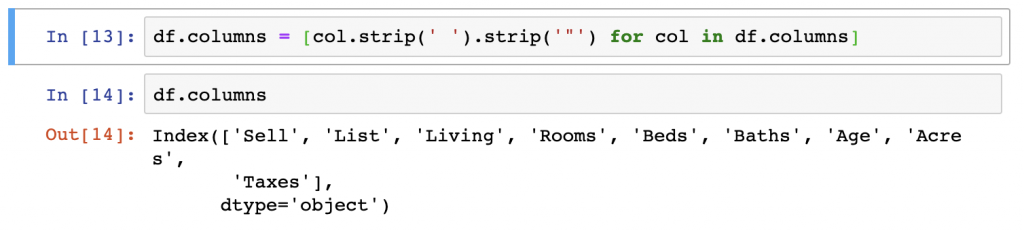
df.columns = [col.strip(' ').strip('"') for col in df.columns]
df.columnsAs you can see all of these approaches work quite well at renaming columns. Additionally, based on one of the responses to a question about this issue on StackOverflow, we see that basically, any operation takes roughly .000 to .001 seconds to perform according to cProfile.
Additionally, in version 0.21 + of Pandas, you can rename columns using the DataFrame.rename() function, which we covered earlier. This function can be used on individual columns at a time to rename variables. This is done within the DataFrame object. A simple example of how it works is below:

df['new'] = df['Beds']/df['Taxes']
df = df.rename(columns={'new':'New'})
df.head()Summary
We’ve covered several approaches to renaming columns using Pandas. These include the use of direct replacement of the DataFrame.columns object, removing extra string functions by looping through column names, and using the str.strip() function to replace unwanted string values. For singular columns, we covered the .rename() function as an option to replace column names which is one of the most used functions for performing this type of operation on your DataFrame.
To see the code for this post on GitHub, you can see the Jupyter Notebook here. For information on how we added columns to the DataFrame, visit our other tutorial.
For further reading on this topic, see the below tutorials and threads from other sources:
- Renaming columns is covered in Chapter 7. Data Wrangling: Clean, Transform, Merge, Reshape from the book Python for Data Analysis
- How to rename columns and row indexes
- Geeks for Geeks approach to renaming columns
- Data Interview Q’s review of the topic