Pandas allows many operations on a DataFrame, the most common of which is the addition of columns to an existing DataFrame. There are several reasons you may be adding columns to a DataFrame, most of which use the same type of operation to be successful. In this post we’ll cover several operations including creating a new column from existing column values; generating static column values; creating a boolean value column; joining data to the DataFrame to add new columns.
Create New Series Values
The first approach we cover is using existing columns to generate a new column. We generate a Pandas Series by dividing two int based columns and setting them equal to the column name you would like to add to your DataFrame. In the below, we added a column called New.
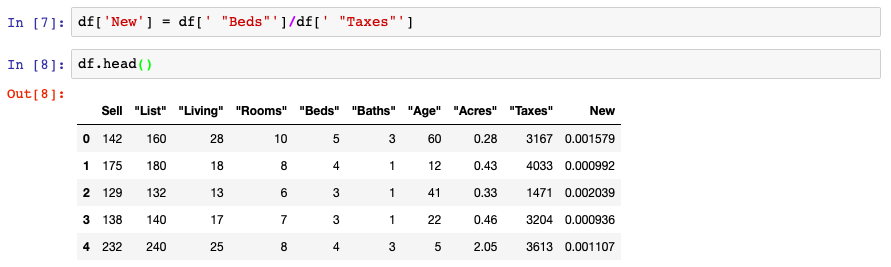
It’s also possible to set other types of objects such as lists equal to your new DataFrame column name. In order to do this, you need to ensure the number of records that you’re inserting into the DataFrame are the same as the number of records in the DataFrame. There’s a quick way to check this on a list and your DataFrame using the len() function on both.
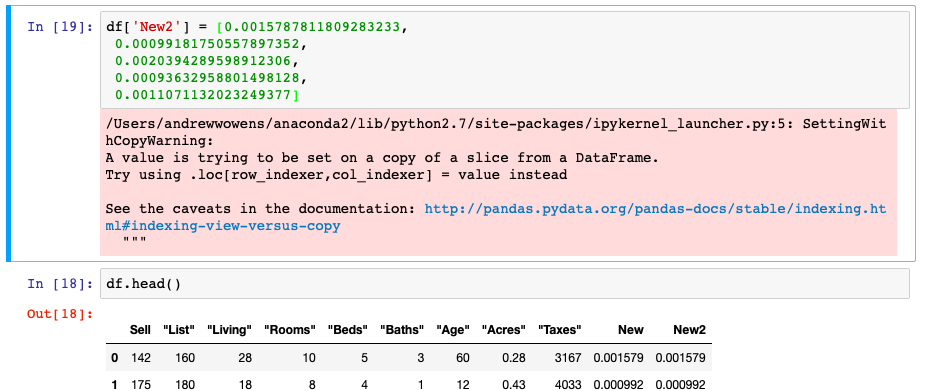
Static Column Data
A third method of adding a column to the DataFrame is to set your new column name equal to a single variable such as an int, float, or string. Here, we quickly assign our example to a single string variable. Once that operation completes, the entire column will be populated with the same value.

Use the Insert Function
One last operation to perform is to use the .insert() function on your DataFrame directly and to declare the column number, name, records/values, and setting allow duplicates to true or false.

Create a New Boolean Based Column
Often we want to create boolean based columns based on specific conditions that we set to help us analyze our data better. Conditional logic in Pandas is possible through several types of functions including mathematic operations (<,>, =, etc.) and use of the DataFrame.where() functions.
In our example below, we’ll make use of the basic mathematic operations function to generate our column based on conditional logic. We will create a variable called “Large_Beds” where the number of Beds, specified in the “Beds” column, are greater than or equal to 5.
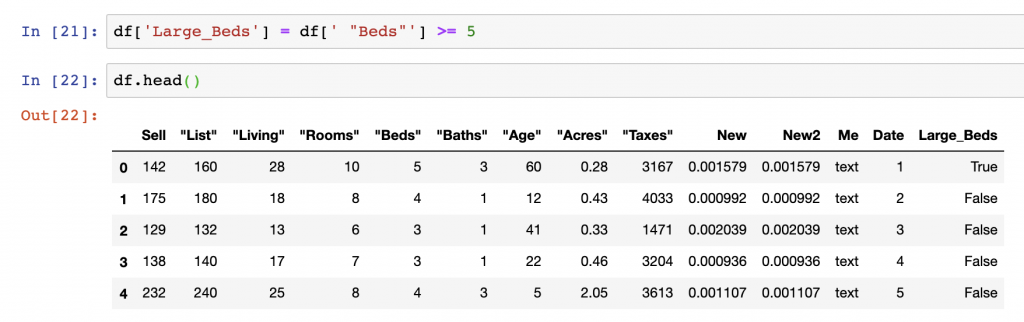
df['Large_Beds'] = df[' "Beds"'] >= 5
df.head()We can see that the output of this is a new column called “Large_Beds” and that the first value of our DataFrame (df) is labeled “True”, indicating that it has greater than or equal to 5 beds.
Join Columns to Your DataFrame
We won’t cover joining and merging data extensively in this tutorial, we will show a basic example of generating a new column from existing data through the following process:
- Getting an average value of Bedrooms (“Beds”) across the two types of values in “Large_Beds”
- Joining that data back to our DataFrame on our Large_Beds column values
- Renaming the column values from our averaged data

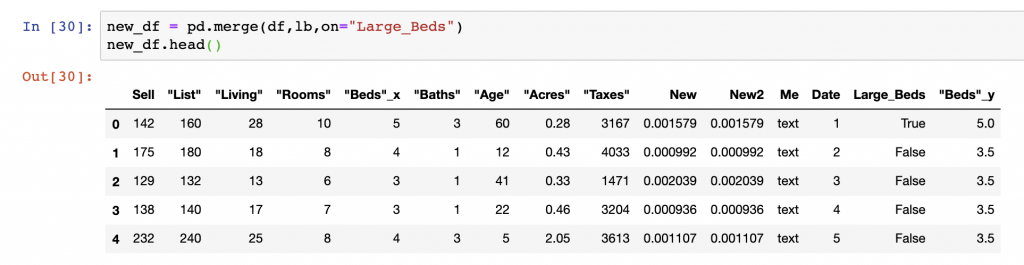

#Generate the average size of beds by Large Beds groupings
lb = df.groupby(["Large_Beds"])[' "Beds"'].mean()
#Merge the data on the Large Beds Groupings
new_df = pd.merge(df,lb,on="Large_Beds")
new_df.head()
#Rename the column to something more interpretable
new_df = new_df.rename(columns={'"Beds"_y':"Avg_Bed_Size"})The last approach can be modified in several different ways, however it is purely for illustrative purposes.
Summary
DataFrames are very maliable objects in Pandas and can be manipulated and added to in many different ways, as this tutorial has shown. We’ve covered creating new values for a DataFrame column through the creation of booleans through conditional logic, adding static column values, generating new values from mathematic formula, joining data, and through the raw insertion of data using the insert() function.
We hope you enjoyed this tutorial and are going to stick around for more support in using the Pandas library. A code repository containing the code in this tutorial can be found here which contains the specific code used in this tutorial.