Building machine learning (ML) models is based on the principle of constructive feedback. You create a model, gather data from indicators, adjust, and repeat until you attain the desired accuracy. The performance of a model can be explained using evaluation measures. The ability of evaluation metrics to discern between model results is a key feature.
Once you finish model building, there are multiple ways to evaluate the model’s accuracy like precision, F1-score, recall, confusion matrix, gain & lift charts, Log-loss, ROC, Rsq/Adj Rsq, Root Mean Square Error (RMSE), etc.
In this article we are going to understand the significance of RMSE, and how it can be calculated.
What Is RMSE?
Before jumping in to learn how to calculate the Root Mean Square Error (RMSE) in Python, let’s first understand its importance.
The RMSE is a scoring rule that measures the average magnitude of error. It is equal to the square root of the average of the squared differences between prediction and actual observation.
The RMSE is a typical method for calculating a model’s error in predicting quantitative data. The formula of RMSE is:
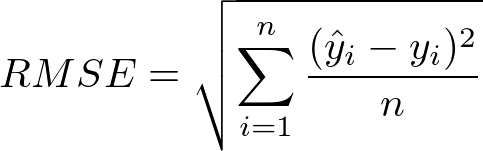
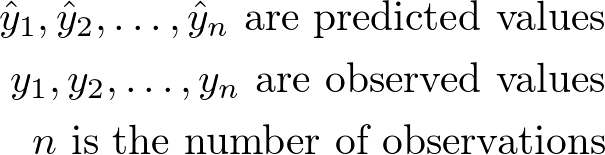
Is Root Mean Square Error Important?
It is particularly useful in machine learning to have a single number to measure the model’s performance, whether during cross-validation, monitoring or training. One of the most used measurements for this is the RMSE. It is a scoring rule that is simple to grasp and compatible with many standard statistical assumptions.
Some keynotes about RMSE:
- RMSE can display big number variations because of the ‘square root’ in its formula
- It avoids the use of absolute error numbers, which is highly undesirable
- Since RMSE takes ‘squared’ values, it gives more reliable results by preventing the cancellation of positive and negative error values. RMSE depicts the likely amount of the error term accurately
- Outlier values have a significant impact on RMSE. Therefore, before using RMSE, make sure you’ve removed any outliers from your dataset
How To Calculate RMSE?
- If the sklearn version >= 0.22.0 then there’s a built-in function with a squared argument (default TRUE). If you set it as FALSE, it will result in RMSE.
from sklearn.metrics import mean_squared_error
rmse = mean_squared_error(y_actual, y_predicted, squared=False)
- If sklearn version < 0.22.0, then you have to takethe root square of the MSE function as shown below:
from sklearn.metrics import mean_squared_error
from math import sqrt
rmse = sqrt(mean_squared_error(y_actual, y_predicted))
Summary
As explained, the standard deviation of the residuals is denoted by RMSE. It basically shows the average model prediction error. The lower the value, the better the fit. It is expressed in the same units as the target variable. It works better when the data doesn’t have any outliers.
References
Official documentation for Mean Squared Error