This article contains affiliate links. For more, please read the T&Cs.
When you’re doing analysis reading data in and out of CSV files is a really common part of the data analysis workflow. Here we’ll do a deep dive into the read_csv function in Pandas to help you understand everything it can do and what to check if you get errors.
read_csv
The basic read_csv function can be used on any filepath or URL that points to a .csv file. In the case below, we point our filename to a publicly available dataset from FSU and store it under the variable file_name.
import pandas as pd
file_name = "https://people.sc.fsu.edu/~jburkardt/data/csv/homes.csv"Then, the file_name variable can be insert into the read_csv function directly
df = pd.read_csv(file_name)Our data is now loaded into the DataFrame variable. We can then see that within our DataFrame variable, df, the data itself by calling the head() function.
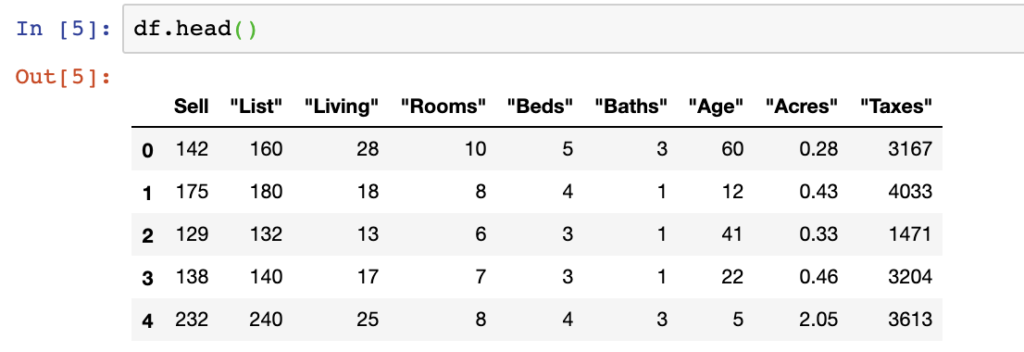
Outside of this basic argument, there are many other arguments that can be passed into the read_csv function that helps you read in data that may be messy or need some limitations on what you want to analyze in Pandas.
header
The header variable helps set which line is considered the header of the csv file. For instance, you may have data on the third line of your file which represents the data you need to mark as your header instead of the first line.
In our example above, our header is default set to 0 which is the first line in the file.
df = pd.read_csv(file_name, header=0)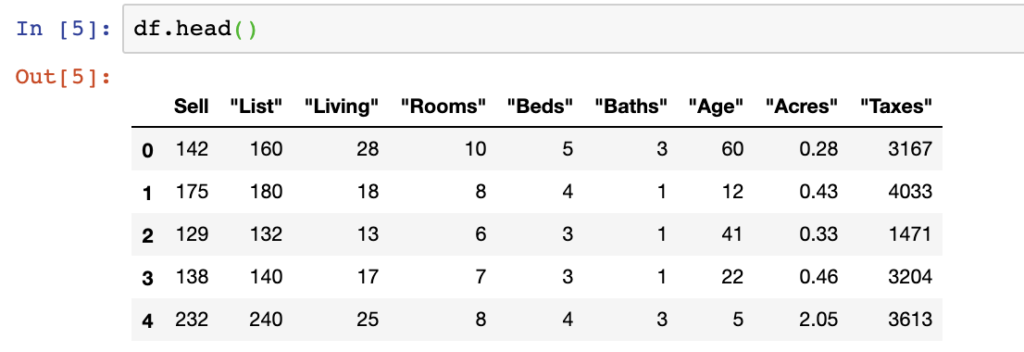
sep
Sep is the separator variable used to separate you columns. Most files use commas between columns in csv format, however you can sometimes have / or | separators (or others) in files.
Although the below will not work with our file, it is an example of how to add a column separator between columns that have a | between them.
df = pd.read_csv(file_name, sep= "|")index_col
index_col is used to set the index, which by default is usually a straight read of your file. However setting a specific column to your index is possible using index_col. In the example below, we set the Sell column to our index:
df = pd.read_csv(file_name, index_col= 0)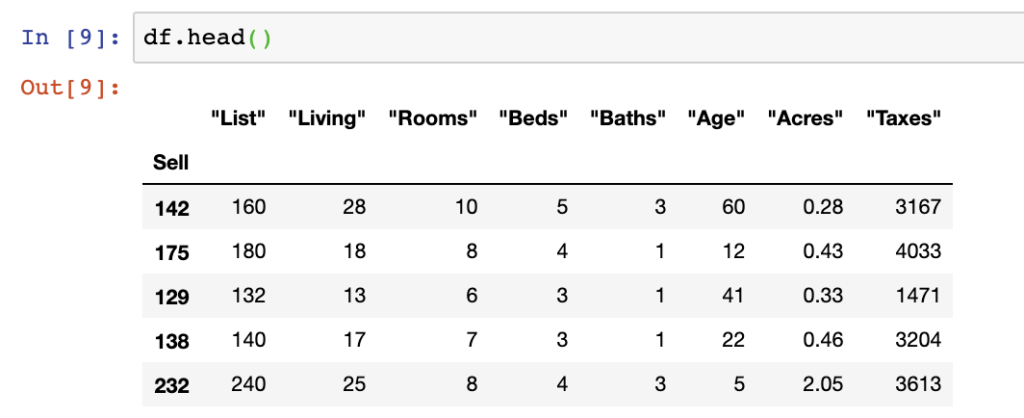
usecols
When you want to only pull in a limited amount of columns, usecols is the function for you.
You have two options on how you can pull in the columns – either through a list of their names (Ex.: Sell) or using their column index (Ex.: 0).
df = pd.read_csv(file_name, usecols = [0,1,2])
skiprows
Skiprows allows you to, well, skip rows. You can start your DataFrame contents as far down as you’d like in your file when it’s read in. In the case below, we jump down 9 rows by setting skiprows=9. However, you’ll see that we don’t have normal column headers as a result because our headers start on line 0 in this dataset.
df = pd.read_csv(file_name, skiprows=9)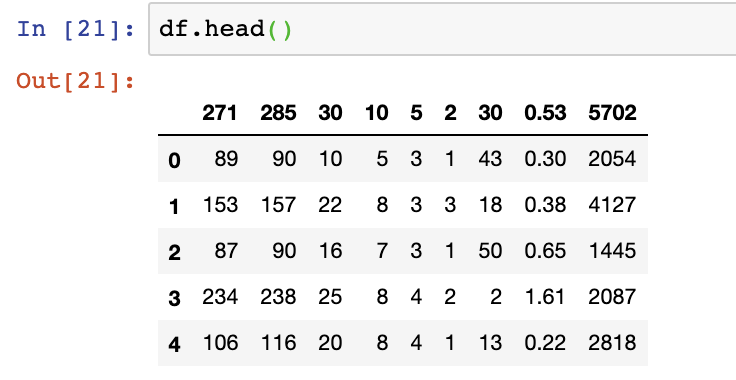
na_values
na_values will replace whatever is entered into it with NaN values. We can essentially replace any string or number with NaN values as long as we specify them clearly. We’ll show two examples of how the function can work.
The first replaces all values in the dataframe with NaN values that are specified within the Sell column. In this case we specify a dictionary of {“Sell”: 175} to replace any value of 175 with NaN values.
df = pd.read_csv(file_name, na_values={"Sell": 175})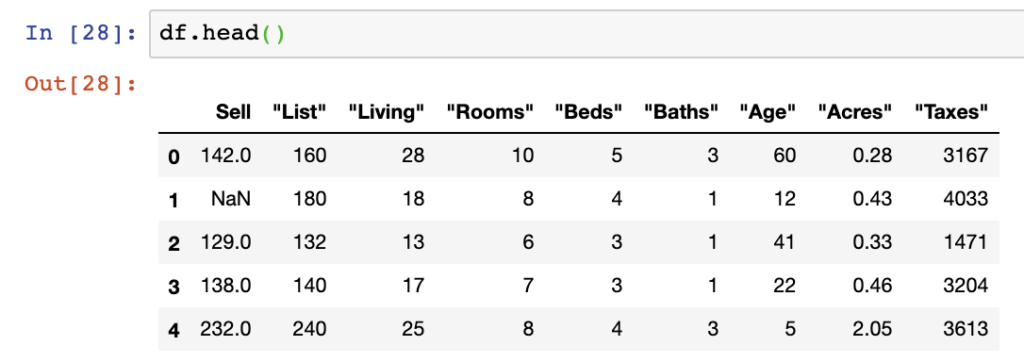
The second example we can’t show you specifically on this DataFrame as it requires text data, but with it we can replace text with NaN values by entering it into a list. When the file is read into the DataFrame any values containing that data will show NaN values.
df = pd.read_csv(file_name, na_values=["Four"])nrows
The nrows argument helps you set the number of rows you’d like to import into the DataFrame from your dataset. In the example below, we set nrows equal to 10 so that we only pull in the top 10 rows of data.
df = pd.read_csv(file_name, nrows=10)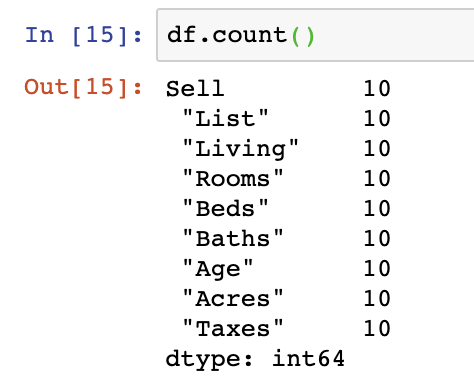
Loading Errors with CSV Files
Pandas users are likely familiar with these errors but they’re common and often require a quick Google search to remember how to solve them.
These common errors include:
- FileNotFoundError – This happens when there is an issue with your file path or directory when you’re trying to access the file you’ve specified. Check your current working directory from where you’re executing your python code from to try and understand how that differs from where you file actually exists.
- UnicodeDecodeError: ‘utf-8’ codec can’t decode byte in position: invalid continuation byte – Maybe you’re trying to import a file with Chinese characters or some other type of non-standard UTF-8 characters. You’ll need to potentially change the encoding type of the file by making edits directly to the file itself.
Summary
Reading csv files is a nearly daily event for most analysts. You never know how high quality the contents will be or how you’ll be able to ingest those files into Pandas.
If you’re opening the file regularly in some kind of job, you’re going to want to understand how to manage the many cases and errors real-world data can throw at you. read_csv helps with that.
You can find more about reading csv files from the below sources:
- Chapter 6 of Python for Data Analysis
- Shane Lynn’s article Python Pandas read_csv – Load Data from CSV Files