This article contains affiliate links. For more, please read the T&Cs.
We often need to write a DataFrame to CSV and other types of files. Thankfully, the Pandas library has some built in options to quickly write out DataFrames to CSV formats.
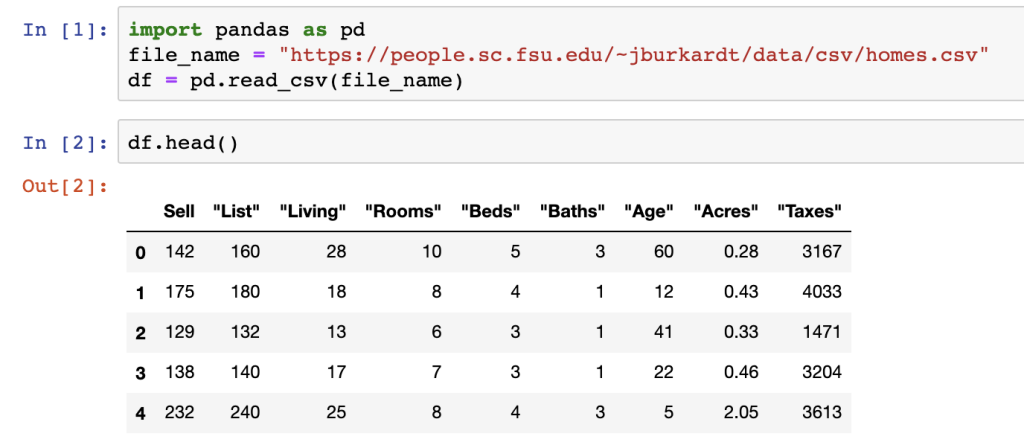
In this tutorial, we’ll show how to pull data from an open-source dataset from FSU to perform these operations on a DataFrame, as seen below
DataFrame.to_csv()
Pandas has a built in function called to_csv() which can be called on a DataFrame object to write to a CSV file. The first argument you pass into the function is the file name you want to write the .csv file to. In the screenshot below we call this file “whatever_name_you_want.csv”.

There are many useful features to the to_csv() function including the ability to encoding and the option to add or remove the detault DataFrame index. In the example below, encoding is set to UTF-8 and the index is set to False so that no index will be written to the .csv file.

An additional feature that some may want when writing to a .csv file is to setup a tab separator between the columns of the DataFrame. This is particularly useful when you’re writing semi-structured text data or data that may contain special characters such as commas.

Performing any of these actions will write the DataFrame to your local directory you are working in. However, you can write the file to any specific path you have local permissions to as another option.
Appending Data to a CSV
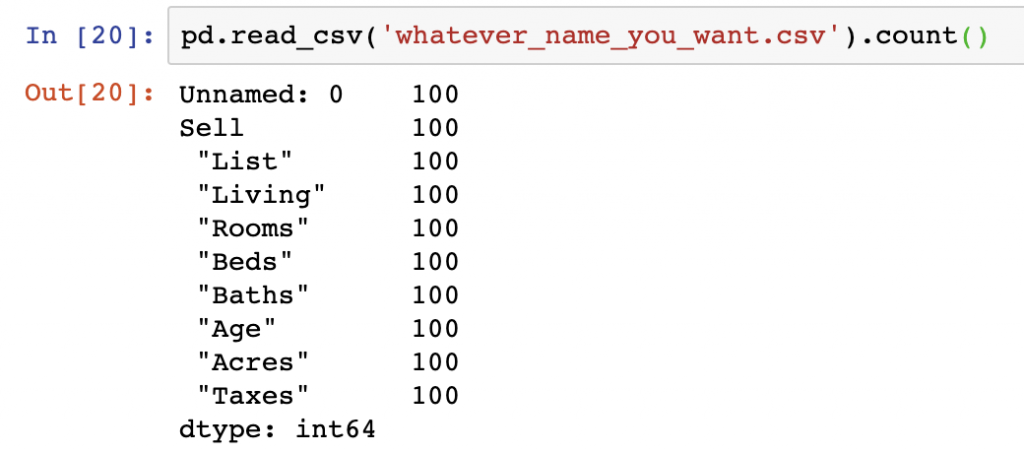
When processing data in a loop or other method, you may want to append records to an existing .csv file. When this is done in Pandas you can use the mode argument and pass in ‘a’ to append data to the existing file. Records will be appended, however unless you pass in the header=False argument along with it, column headers will be written to the same file, duplicating the header originally written to the file.

Now the we appended data without a header in the action above, we can see using the .count() function that we’ve doubled the size of the DataFrame contents from 50 original records to 100 records.
Additional Arguments When Using to_csv()
The following arguments are in no specific order of importance but have all been useful to your author over time for various purposes when handling files.
chunksize is an extremely useful when the size of the DataFrame is very large (think 100k+ rows). It can be easily added to the to_csv() function:

df.to_csv('whatever_name_you_want.csv', mode='a', header=False, index=False, chunksize=10000)compression is an equally important feature when handling large files as you can setup functions to write to .gzip files

df.to_csv(‘whatever_name_you_want.csv’, mode=’a’, header=False, index=False, compression=’gzip’)
encoding is the last argument that I’ve found useful in the past when handling certain types of files. The default is to utf-8 however you have the option of using other formats, which in my opinion is a rare occurrence.
Summary
After this tutorial, you should be able to know how to handle writing your DataFrame contents to a CSV file in Pandas. We’ve covered a variety of options for handling appending to CSV files and standard arguments useful for managing your data export. To see the the code surfaced in the screenshots above, please visit our GitHub repository on Data Analysis. More information on common Pandas operations can be found in our detailed tutorials. Additionally, more on this can be found in Python for Data Analysis’s Chapter 6, “Data Loading, Storage, and File Formats”.