This article contains affiliate links. For more, please read the T&Cs.
Despite the mass investment by third parties to provide API access to reports and data that their customers want, email still remains a fundamental part of the data transfer process. For Google Analytics, they provide a litany of backend API, Data Export, and other services to provide data to their customers for further analysis, however, sending data around by email is still a key feature in their application. Often times, you may not be able to access an API for security reasons and email is the last resort.
In this tutorial, we show you how to extract data from emails sent from Google Analytics to a Gmail account. We’ll be using only the Python Standard Library, imaplib, and email to achieve this.
Getting Your Gmail Account Setup & Secure
The first thing we need to think about when accessing email accounts is security. In Google, if you have 2-Step Verification turned on (which you should, so if you haven’t go turn it on), you will need to create an individualized App Password for accessing your account from a given application – in this case, our Python interpreter.
Go to the Security settings of your account in Google and look for the “Signing in to Google” section where you should see “App passwords” as shown below. Click on this link and setup your password to read from your Gmail and your local machine, or if you plan to use a server, select “Other”.
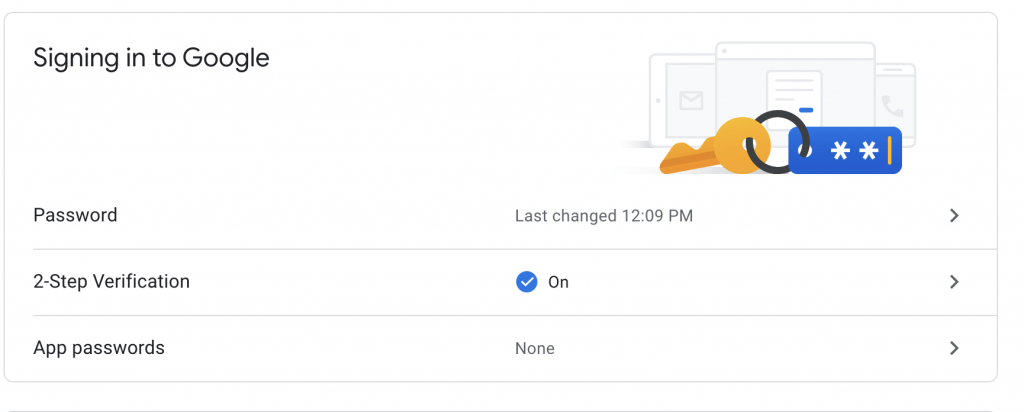
Once you’ve setup your password, you’ll need to save it somewhere secure so you can use it to access your Gmail emails in the Python script. If you try to proceed with this tutorial without setting up an app password and you have 2-Step Authentication on, you’ll quickly run into this error:

Structuring The Python Code
The overall structure of the script we’ll use today is as follows:
- Import required libraries
- Input hard-coded variables
- Generate functions for:
- Creating the search logic of our Inbox
- Accessing the contents of a specific email to access a file for download
- Saving the given file
What we won’t get into in this post is the detailed setups of cleaning up messy file formats in CSV (or any other format). We’re just interested in downloading these files from email for further cleaning and analysis down the line. That process of manipulating and cleansing files for analysis we’ll cover in a later post.
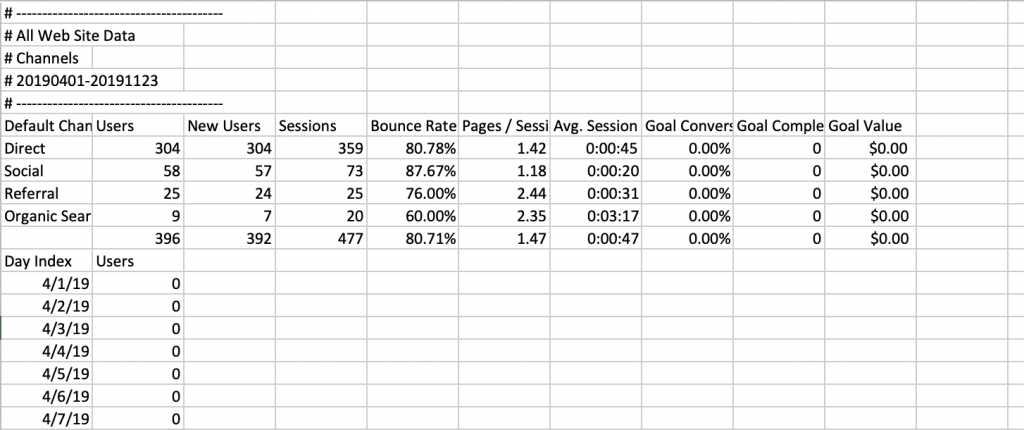
As you can see from the below data file we’re going to ingest in this post (a completely arbitrary file sent from Google Analytics), the file formatting is not immediately useful for analysis once downloaded, there are many steps to take after downloading to make this data useful for analysis.
Inspecting the Email Structure
Before you get started working through your Python code, you need to take a look at the basic structure of the emails that you’re receiving. Firstly, the imap and email servers have special means of searching for content. You do not want to download all the files on your email account, as if you’re like me, that will represent gigabytes of historic email contents.
The items to pay attention to for structuring your ability to pull down files from emails are:
- The Subject of the email (see below)
- The Sender
- The Attachment File Name
- The Datetime/Received time of the email
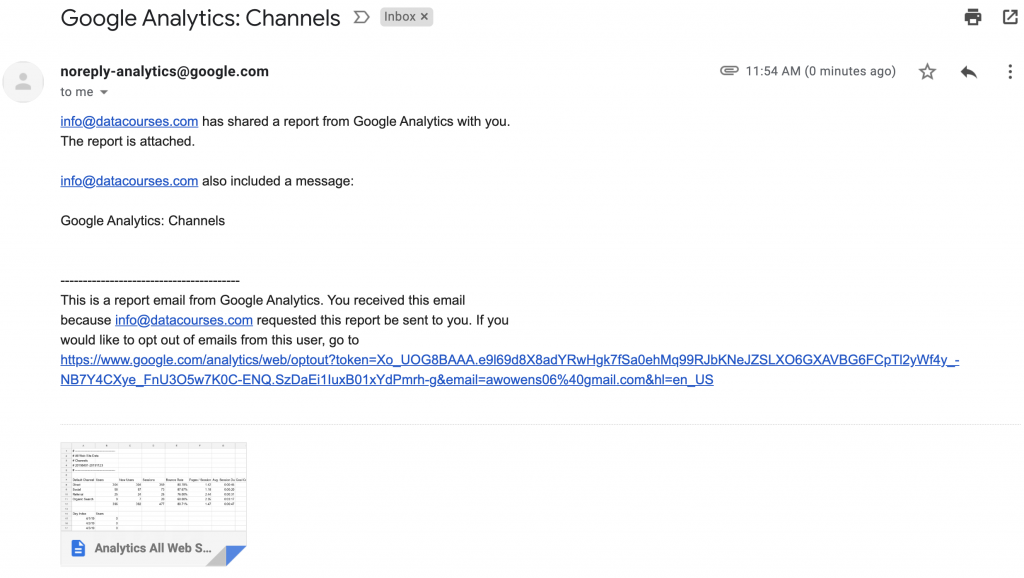
Once you understand a bit more about the structure of your email, you can proceed to coding out how to pull down the email contents.
Pulling Down Email Contents
The first step in our Python script is to, as always, import the libraries we’re going to use in our script:
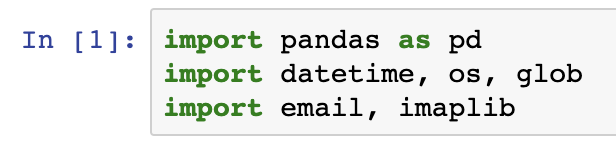
import pandas as pd
import datetime, os, glob
import email, imaplibThe next step is to enter in some hard-coded variables into your script for accessing your computers current working directory as well as the connection details to Gmail:

cwd = os.getcwd()
EMAIL_UN = 'EMAIL'
EMAIL_PW = 'GOOGLE APP PROVIDED PASSWORD'The next step is to structure a function to generate the subject header details that will be used to search your email server for, in this case, a unique email. In our case, we want to match the exact subject header of our email and only pull down the file for a specific day. This last piece of logic is very important if you have multiple emails being delivered every day.

def details(subject_header,date=(datetime.datetime.now()-datetime.timedelta(1)).strftime("%d-%b-%Y")):
#EMAIL SEARCH CRITERIA
search_criteria = '(ON '+date+' SUBJECT "'+subject_header+'")'
return search_criteriaThe longest structure of our code* will be what’s used to actually access our email using imap and the email libraries. The most important functions of the script are the following:
- Logging into Gmail using your credentials at the imap.gmail.com url
- Searching your email server for the given Subject generated
- Iterating through the results of your email contents
- Writing the attached file to the current working directory detailed earlier in our script
def attachment_download(SUBJECT):
un = EMAIL_UN
pw = EMAIL_PW
url = 'imap.gmail.com'
detach_dir = '.' # directory where to save attachments (default: current)
# connecting to the gmail imap server
m = imaplib.IMAP4_SSL(url,993)
m.login(un,pw)
m.select()
resp, items = m.search(None, SUBJECT)
# you could filter using the IMAP rules here (check http://www.example-code.com/csharp/imap-search-critera.asp)
items = items[0].split() # getting the mails id
for emailid in items:
resp, data = m.fetch(emailid, "(RFC822)") # fetching the mail, "`(RFC822)`" means "get the whole stuff", but you can ask for headers only, etc
email_body = data[0][1] # getting the mail content
mail = email.message_from_string(str(email_body)) # parsing the mail content to get a mail object
#Check if any attachments at all
if mail.get_content_maintype() != 'multipart':
continue
print("["+mail["From"]+"] :" + mail["Subject"])
# we use walk to create a generator so we can iterate on the parts and forget about the recursive headach
for part in mail.walk():
# multipart are just containers, so we skip them
if part.get_content_maintype() == 'multipart':
continue
# is this part an attachment:
if part.get('Content-Disposition') is None:
continue
filename = part.get_filename()
counter = 1
# if there is no filename, we create one with a counter to avoid duplicates
if not filename:
filename = 'part-%03d%s' % (counter, 'bin')
counter += 1
att_path = os.path.join(detach_dir, filename)
#Check if its already there
if not os.path.isfile(att_path):
# finally write the stuff
fp = open(att_path, 'wb')
fp.write(part.get_payload(decode=True))
fp.close()
print(str(filename)+ ' downloaded')
return filenameSummary
Running your script through each of these functions should end up with a fully downloaded email file. Not only can this be used on CSV files, but files of truly any type.
There are many articles available on how to work with the imaplib library in Python, but I recommend checking out Chapter 13 in the Python 3 Standard Library by Example that exclusiviely covers working with email. It’s also a really great reference for anything in the standard library, which covers a lot of ground.
For more information on the script we generated here today, you can access the code on our GitHub account, here.
*Parts of this code was originally pulled from a post that I can no longer find publicly available. I’ve been using it since 2015. If you were the one who wrote it, send me a note so I can thank+reference you.