Removing unnecessary columns and rows is critical to manipulating data within a Pandas DataFrame. This tutorial covers how to delete single columns, multiple columns, single rows, and multiple rows using various conditions and individual selection.
The first step we will take is to start by loading some real data into a DataFrame. In this tutorial, we’ll be exploring an open-source dataset from FSU, as seen below:
Delete Single Columns
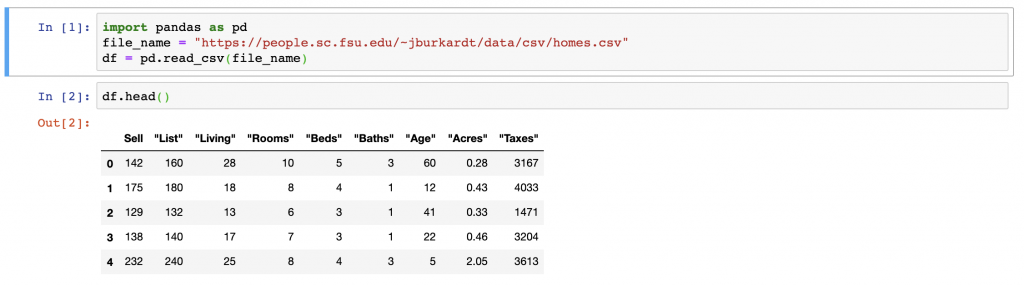
The core function for deleting an individual column (or multiple columns) is the .drop() function in Pandas. The function itself takes in multiple parameters such as labels, axis, columns, level, and inplace – all of which we cover in this post.
From the above columns we will first remove the ‘Sell’ column from the DataFrame (df). In this case, we pass in several parameters into the function, the first is the Sell column as our labels parameter, the second is the value 1 which is passed in as the axis parameter, and lastly we override the inplace function with True. The labels parameter points to the column or index (representing columns) that we want to remove. axis can be either 0 or 1, 1 representing the selection of columns being deleted and 0 being an index. inplace being set to True means that we don’t have to reassign the DataFrame to another variable but to remove the columns directly in the existing object.
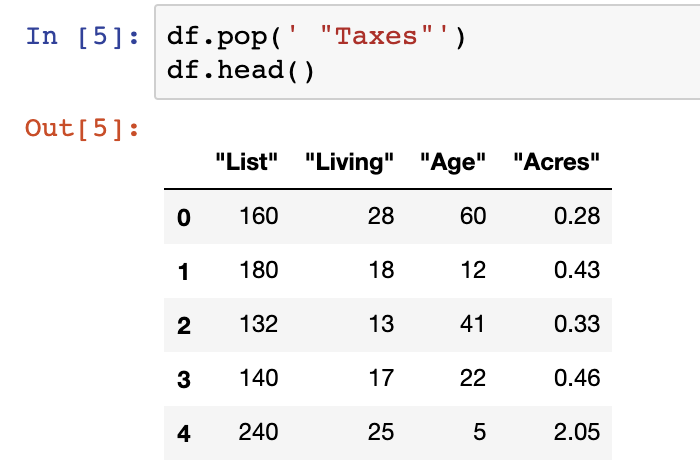
Another method to delete individual columns is the .pop() function. It removes the column explicitly defined in the item parameter in the function.
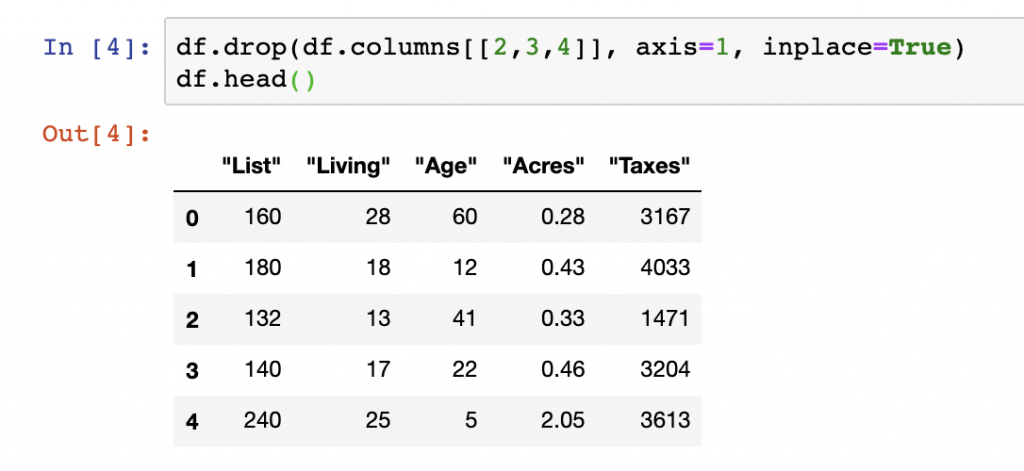
Python’s del function can also be used to remove a selected column(s) from a DataFrame. Both .pop() and the del approach act as the inplace=True function does, meaning that columns can be deleted without variable reassignment.

Delete Multiple Columns
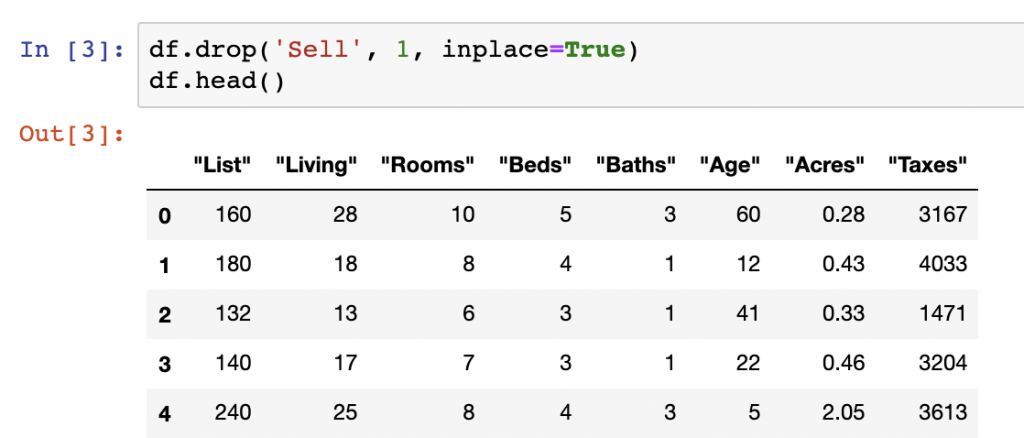
When deleting multiple columns from a DataFrame, we can also make use of the .drop() function from earlier but this time using the index of a column to identify the columns to drop. In the below, we use the DataFrame.columns function to select the columns we want to delete by their index number.
Delete Rows
Just as we used .drop() to delete columns we can use similar calls using the function to delete rows. When the axis parameter is set to 0, the deletion of rows is selected.
Additionally, we can make use of row selection techniques for filtering out values we don’t want in a given DataFrame, such as the removal of NaN or NULL values.
One of these approaches is to remove values that are in a specific index within our DataFrame. This can be accomplished, for example on the first 5 rows in a DataFrame by using the .iloc function – df = DataFrame.iloc[5:]
Delete Rows Using Conditions
Multiple conditions can be used to select specific rows from a DataFrame. We’ve covered most of these functions such as operators, .query(), and .loc in another post which we recommend reviewing for selecting or removing specific rows using conditions.
Delete Duplicative Rows
Although there are no duplicative rows in the FSU dataset we’re working with in this post, this is a common issue when importing or manipulating data from various data sources.
We can address this by calling the duplicated function in Pandas. While the logic is somewhat complex, we can call the following function to deal with these troublesome rows:
DataFrame.loc[~DataFrame.index.duplicated(keep=’first’)]
After this tutorial you should be able to Delete Rows or Columns Pandas. For the code surfaced in the screenshots above, please visit our GitHub repository on Data Analysis. More information on common Pandas operations can be found in our detailed tutorials.