While studying Data Science, we often come across DataFrames ready to be used. Normally, those DataFrames already contains all of the samples to be analyzed. However, there are some real-life scenarios where data sources are always streaming new samples of data. For that reason, we’ll see different ways to complete the job of adding rows to a Pandas Dataframe.
Firstly, three ways of adding data using Pandas built-in methods are going to be presented. Secondly, the reader will see practical examples of appending/adding new data to a DataFrame.
Appending data using Pandas:
Following the introduction, we will create two Dataframes based on movie ratings from IMDb for the sake of showing how the methods work.
https://gist.github.com/gtfuhr/21b4276edad3e9cfda79f82cdb3567c9#file-createmoviedf-py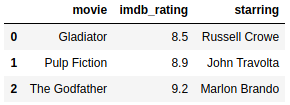
Following the creation of the data, a new sample has just arrived!
https://gist.github.com/gtfuhr/21b4276edad3e9cfda79f82cdb3567c9#file-createnewmoviedf-py
What do we do now that we have the original data and a new sample? Let’s add them together! See how to add this row by looking at the next three techniques:
Adding rows using pd.concat:
Pandas concat is a function that can be imported from pandas, for example, you can take a list of Pandas DataFrames or Pandas Series and concatenate them.
Main arguments of Pandas Concat:
objs:
You don’t need to name this argument, because this is the list of Series or DataFrames to be concatenated together.
Example:
https://gist.github.com/gtfuhr/21b4276edad3e9cfda79f82cdb3567c9#file-concatmoviesdf-py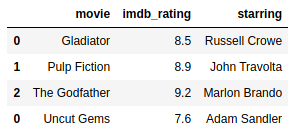
Wait! Look at our index! We can fix it by learning to use the argument ignore_index properly later in this section.
ignore_index:
It looks like later is now! It’s important to consider the use of the ignore_index option while appending data. For example, if it’s an index to identify only the position of a sample in the DataFrame, you can drop the index while appending new data. Despite of that, be careful while dealing with Time-Series Data, because the index normally is some “timestamp”, a very important feature of the data. For that reason, we’ll see how to fix the index of our DataFrame to make it a unique index after some data is added:
Example with ignore_index set to false:
https://gist.github.com/gtfuhr/21b4276edad3e9cfda79f82cdb3567c9#file-ignoreindex-pyWith ignore_index set to false, the original index from the new_movie DataFrame is preserved. In this case, we don’t want that, so we’re going to ignore the index:
Example, with ignore_index set to True:
https://gist.github.com/gtfuhr/21b4276edad3e9cfda79f82cdb3567c9#file-ignoreindextrue-py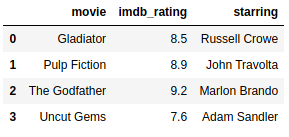
axis:
Here we select if we will add new samples of data by setting the axis to 0. However, we are going to add some features by setting the axis to 1.
Example:
Suppose we need to add a new feature that tells how many Oscar the movie has earned. For this reason, setting the axis argument properly will help us to add this new feature to the data.
Example with axis set to 0, the default:
We can see that nothing changes in this output. This is normal since we set the concat function to add data in the index. In other words, adding data in the index means that new samples of data will be added to the DataFrame vertically.
https://gist.github.com/gtfuhr/21b4276edad3e9cfda79f82cdb3567c9#file-axis0-pyHere we have the movie data added together exactly as we did before.
Example:
Suppose we got a feature that tells how many Oscar the movie has earned. Undoubtedly, setting the axis argument properly will help us to add this new feature to the data.
https://gist.github.com/gtfuhr/21b4276edad3e9cfda79f82cdb3567c9#file-addfeature-py
Our new feature can be added to our movie data by setting the axis to 1. Consequently, this makes us add data vertically, which means that new columns will be added to our DataFrame. Check it out in the example below:
https://gist.github.com/gtfuhr/21b4276edad3e9cfda79f82cdb3567c9#file-axis1-py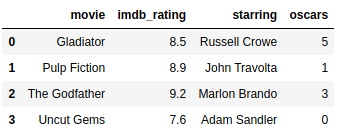
verify_integrity:
If this argument is set to true, Pandas will check if there are no duplicate rows.
OBS: (Remember, this can be computationally expensive depending on the size of the concatenation):
Example:
https://gist.github.com/gtfuhr/21b4276edad3e9cfda79f82cdb3567c9#file-withoutverifyintegrity-py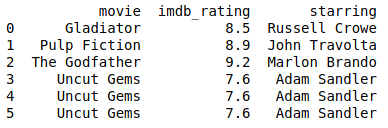
Pandas didn’t show to us that there is duplicate data on the DataFrame because verify_integrity was set to False.
Example with verify_integrit set to True:
https://gist.github.com/gtfuhr/21b4276edad3e9cfda79f82cdb3567c9#file-verifyintegrity-py
Due to verify_integrity, this concatenation with duplicate data raises an error.
In addition, more information into joining data can be found in our other article: Concatenate, Merge, And Join Data with Pandas.
Adding rows using DataFrame.append:
The DataFrame method append has the same behavior as pd.concat when we talk about ignore_index, so we’re going to set it to True.
https://gist.github.com/gtfuhr/21b4276edad3e9cfda79f82cdb3567c9#file-append-py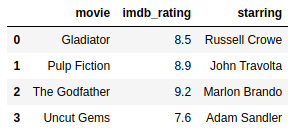
Finally, let’s test how the append operation went and check if the results are the same from the pd.concat operation. To compare two DataFrames properly, we need to drop their index, as can be seen at this question from Stack Overflow.
https://gist.github.com/gtfuhr/21b4276edad3e9cfda79f82cdb3567c9#file-comparation-py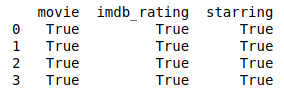
Setting rows using DataFrame.iloc and DataFrame.loc:
At certain times, for example, you will need to correct a row from the original data. To illustrate that, we’ll use the DataFrame.loc method:
Using DataFrame.iloc:
https://gist.github.com/gtfuhr/21b4276edad3e9cfda79f82cdb3567c9#file-iloc-py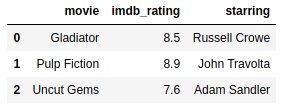
This operation also substitutes the third row of the movie_data DataFrame with the first row from the new_movie DataFrame. However, the iloc function can only receive location-index by integers.
Using DataFrame.loc:
https://gist.github.com/gtfuhr/21b4276edad3e9cfda79f82cdb3567c9#file-loc-pySpecifically, this operation substitutes the third row of the movie_data DataFrame with the first row from the new_movie DataFrame. Indexing by an integer with loc is almost the same as using iloc, but loc can be used in different ways. It also can select rows that obey a certain rule. See in the following example:
https://gist.github.com/gtfuhr/21b4276edad3e9cfda79f82cdb3567c9#file-loc2-py
Practical scenario:
We are going to use the OpenML as a data source to fetch data. Consequently, we can simulate an environment of an original dataset and a novel dataset. Additionally, scikit-learn provides us a handy function to fetch open-source datasets from the site. In this case, we’re going to use the credibility data collected from a group of people. And, last but not least, a special thanks to Dr. Hans Hofmann for open sourcing this data.
https://gist.github.com/gtfuhr/21b4276edad3e9cfda79f82cdb3567c9#file-fetchcreditdataopenml-pyAdditionally, after fetching data and creating a DataFrame, we’re going to split this data into datasets, simulating a two survey scenario:
https://gist.github.com/gtfuhr/21b4276edad3e9cfda79f82cdb3567c9#file-createfirstsurvey-py
After that, we take the last 400 samples of data using pandas indexing. Following this, we create a DataFrame with the name second_survey with this data.
https://gist.github.com/gtfuhr/21b4276edad3e9cfda79f82cdb3567c9#file-createsecondsurvey-py
During this section, our job is to apply the techniques learned in the first section. For this reason, take a look at how this can be approached:
Adding rows to a Pandas Dataframe using pd.concat
https://gist.github.com/gtfuhr/21b4276edad3e9cfda79f82cdb3567c9#file-concat-py
Adding rows to a Pandas Dataframe using DataFrame.append
https://gist.github.com/gtfuhr/21b4276edad3e9cfda79f82cdb3567c9#file-appendsurveydata-pySetting rows to a Pandas Dataframe using DataFrame.iloc
Additionally, think about this scenario: we got some bad news about the credibility data that we’re working with. The last four hundred samples of data from the first survey have not been collected using Stratified sampling. But the Survey company also send the results of a second survey. This time the survey used Stratified sampling. So, let’s replace the last four hundred data samples from the first survey with the new data that has arrived.
https://gist.github.com/gtfuhr/21b4276edad3e9cfda79f82cdb3567c9#file-locsurveydata-py
You’re ready to append new data to your DataFrames
Wrapping up, we just saw how to append data using pandas built-in methods and their most important arguments. So, through the correct use of those functions, we can easily add new data to an existing DataFrame. Subsequently, the reader could read examples of appending data using append and concat. Finally, that’s all folks, thanks for reading and have a Pythonic day!
In addition to this, do you want to check the documentation of the functions used in this tutorial? If so, they’re available below:
At last, check the code utilized in this post is available here on Github. In addition, if you like Data Science, don’t forget to check our other posts at Data Courses.